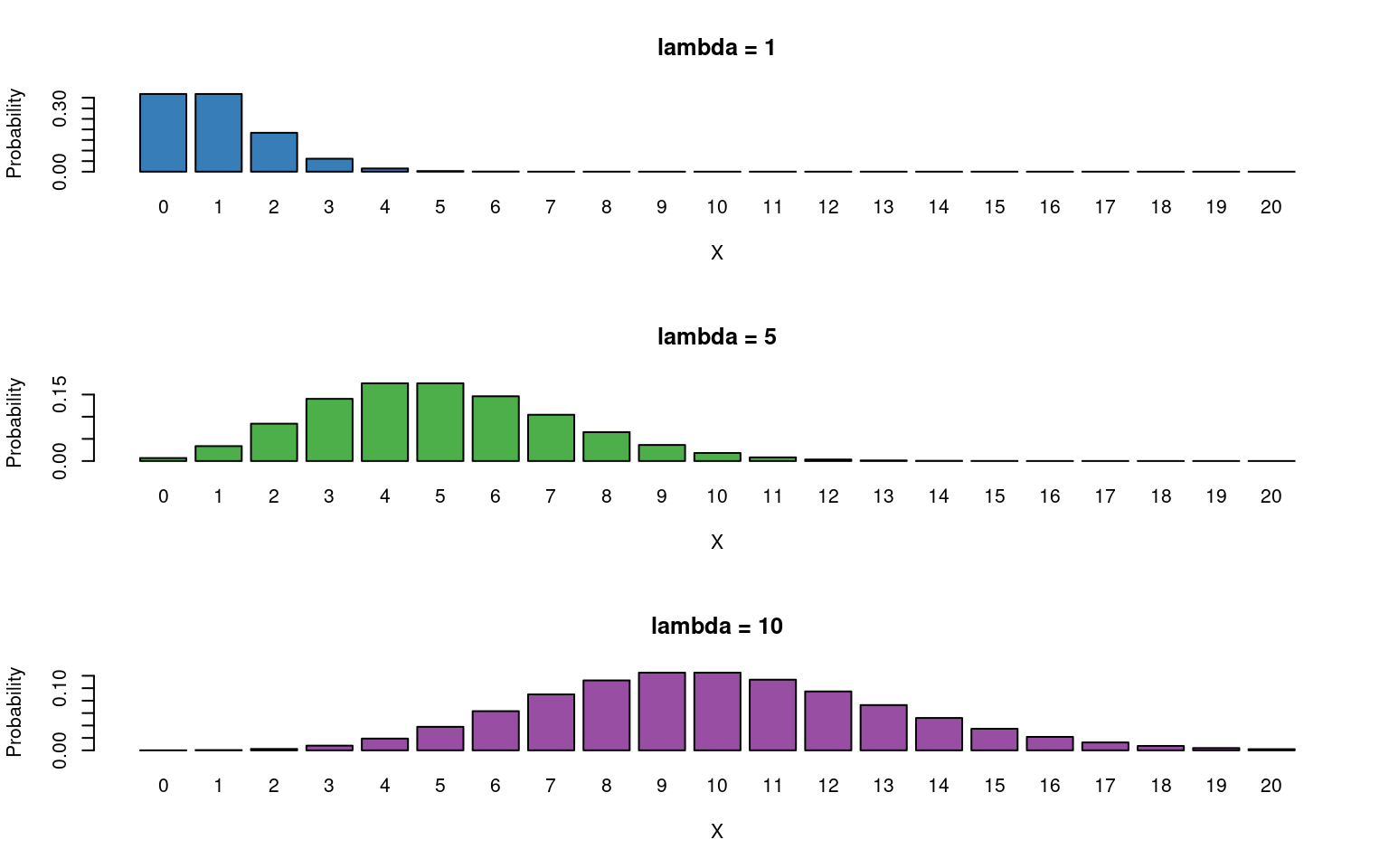
26 Poisson regression (for count data or rate data)
Count or rate data are ubiquitous in the life sciences (e.g number of parasites per microlitre of blood, number of species counted in a particular area). These type of data are discrete and non-negative. In such cases assuming our response variable to be normally distributed is not typically sensible. The Poisson distribution lets us model count data explicitly.
Recall the simple linear regression case (i.e a GLM with a Gaussian error structure and identity link). For the sake of clarity let’s consider a single explanatory variable where \(\mu\) is the mean for Y:
\[ \begin{aligned} \mu & = \beta_0 + \beta_1X \end{aligned} \]
The mean function is unconstrained, i.e the value of \(\beta_0 + \beta_1X\) can range from \(-\infty\) to \(+\infty\). If we want to model count data we therefore want to constrain this mean to be positive only. Mathematically we can do this by taking the logarithm of the mean (the log is the default link for the Poisson distribution). We then assume our count data variance to be Poisson distributed (a discrete, non-negative distribution), to obtain our Poisson regression model (to be consistent with the statistics literature we will rename \(\mu\) to \(\lambda\)):
\[ \begin{aligned} Y & \sim \mathcal{Pois}(\lambda) \\ \log{\lambda} & = \beta_0 + \beta_1X \end{aligned} \]
Note - the relationship between the mean and the data is modelled by Poisson variance. The relationship between the predictors and the mean is modelled by a log transformation.
The Poisson distribution has the following characteristics:
- Discrete variable, defined on the range \(0, 1, \dots, \infty\).
- A single rate parameter \(\lambda\), where \(\lambda > 0\).
-
Mean = \(\lambda\)
- Variance = \(\lambda\)
So we model the variance as equal to the mean - as the mean increases so does the variance.

So for the Poisson regression case we assume that the mean and variance are the same. Hence, as the mean increases, the variance increases also (heteroscedascity). This may or may not be a sensible assumption so watch out! Just because a Poisson distribution usually fits well for count data, doesn’t mean that a Gaussian distribution can’t always work.
Recall the link function between the predictors and the mean and the rules of logarithms (if \(\log{\lambda} = k\)(value of predictors), then \(\lambda = e^k\)):
\[ \begin{aligned} \log{\lambda} & = \beta_0 + \beta_1X \\ \lambda & = e^{\beta_0 + \beta_1X } \end{aligned} \] Thus we are effectively modelling the observed counts (on the original scale) using an exponential mean function.
26.1 Example: Cuckoos

In a study by Kilner et al. (1999), the authors studied the begging rate of nestlings in relation to total mass of the brood of reed warbler chicks and cuckoo chicks. The question of interest is:
How does nestling mass affect begging rates between the different species?
| Mass | Beg | Species |
|---|---|---|
| 9.637522 | 0 | Cuckoo |
| 10.229151 | 0 | Cuckoo |
| 13.103706 | 0 | Cuckoo |
| 15.217391 | 0 | Cuckoo |
| 16.231884 | 0 | Cuckoo |
| 20.120773 | 0 | Cuckoo |
The data columns are:
- Mass: nestling mass of chick in grams
- Beg: begging calls per 6 secs
- Species: Warbler or Cuckoo
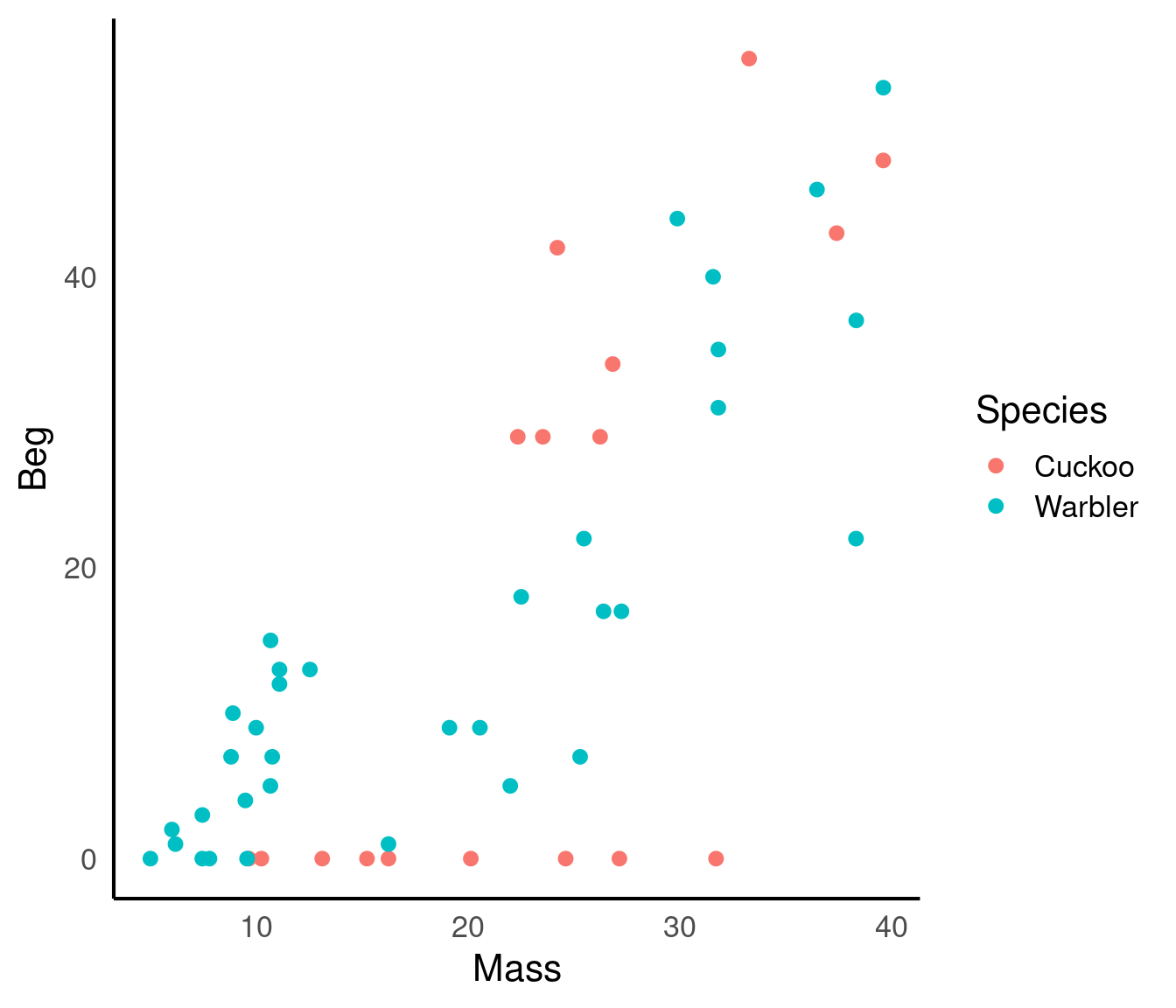
There seem to be a relationship between mass and begging calls and it could be different between species. It is tempting to fit a linear model to this data. In fact, this is what the authors of the original paper did; reed warbler chicks (solid circles, dashed fitted line) and cuckoo chick (open circles, solid fitted line):
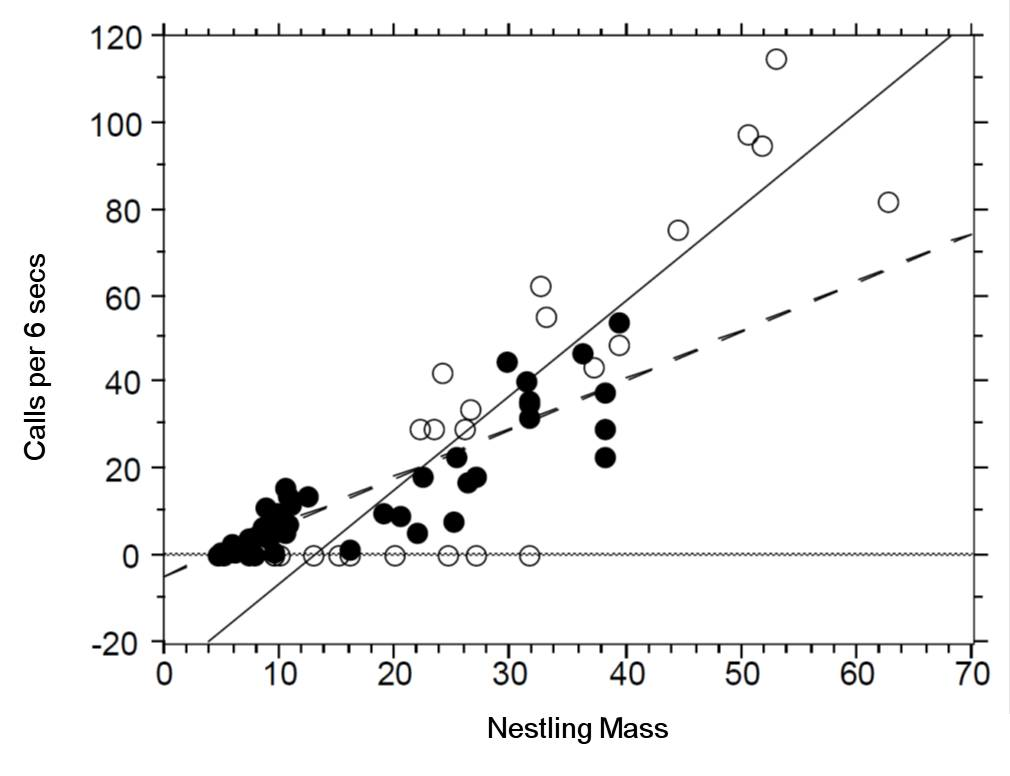
This model is inadequate. It is predicting negative begging calls within the range of the observed data, which clearly does not make any sense.
Let us display the model diagnostics plots for this linear model.
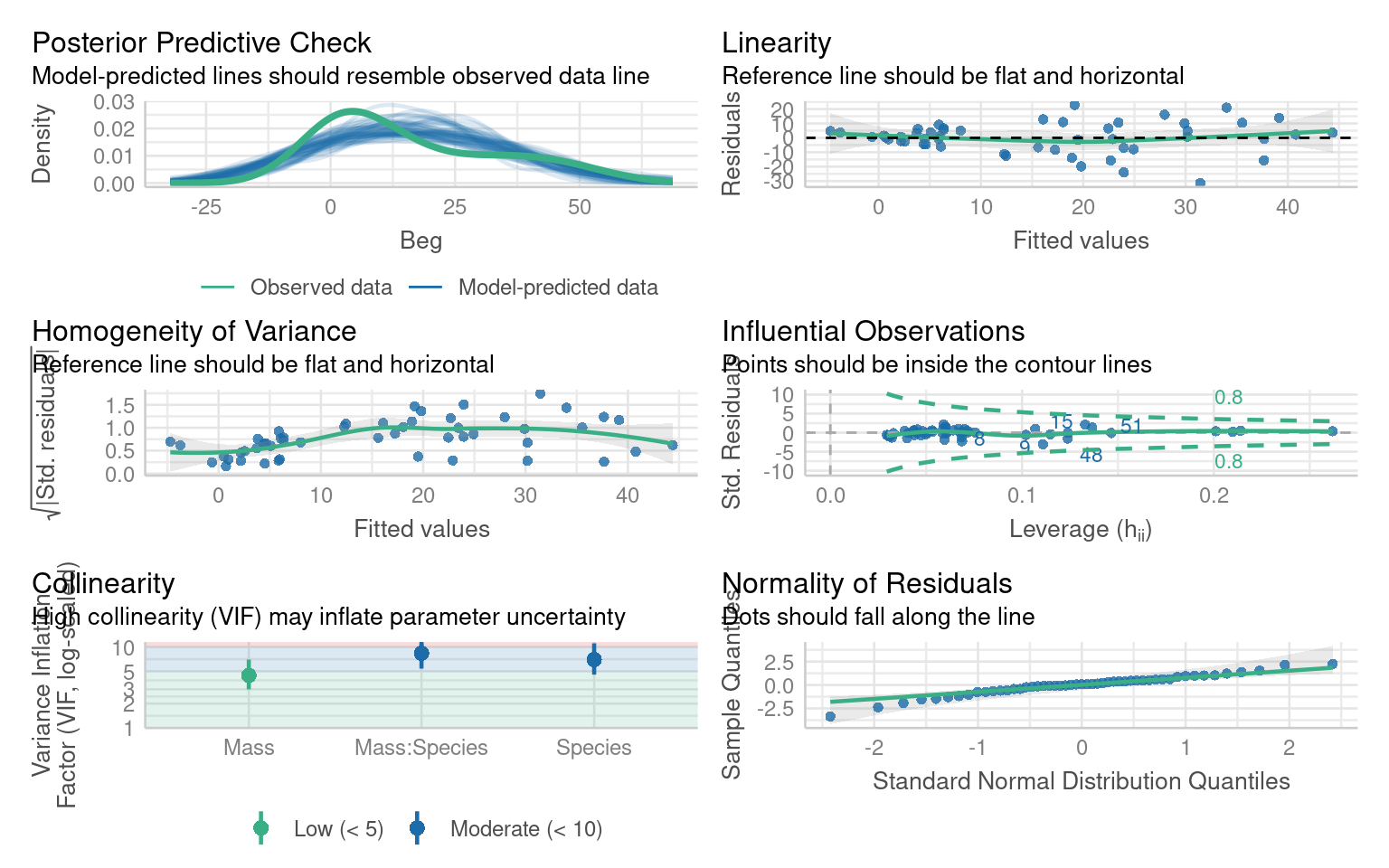
The residuals plot depicts a strong “funnelling” effect, highlighting that the model assumptions are violated. We should therefore try a different model structure.
The response variable in this case is a classic count data: discrete and bounded below by zero (i.e we cannot have negative counts). We will therefore try a Poisson model using the canonical log link function for the mean:
\[ \log{\lambda} = \beta_0 + \beta_1 M_i + \beta_2 S_i + \beta_3 M_i S_i \]
where \(M_i\) is nestling mass and \(S_i\) a dummy variable
\[ S_i = \left\{\begin{array}{ll} 1 & \mbox{if $i$ is warbler},\\ 0 & \mbox{otherwise}. \end{array} \right. \]
The term \(M_iS_i\) is an interaction term. Think of this as an additional explanatory variable in our model. Effectively it lets us have different slopes for different species (without an interaction term we assume that both species have the same slope for the relationship between begging rate and mass, and only the intercept differ).
The mean regression lines for the two species look like this:
- Cuckoo (\(S_i=0\))
\[ \begin{aligned} \log{\lambda} & = \beta_0 + \beta_1 M_i + (\beta_2 \times 0) + (\beta_3 \times M_i \times 0)\\ \log{\lambda} & = \beta_0 + \beta_1 M_i \end{aligned} \]
Intercept = \(\beta_0\), Gradient = \(\beta_1\)
Warbler (\(S_i=1\))
\[ \begin{aligned} \log{\lambda} & = \beta_0 + \beta_1 M_i + (\beta_2 \times 1) + (\beta_3 \times M_i \times 1)\\ \log{\lambda} & = \beta_0 + \beta_1 M_i + \beta_2 + \beta_3M_i\\ \end{aligned} \]
26.2 Activity 1: Fit the model
Fit a Poisson GLM
Fit the same model but with the
glm()functionSet the family to poisson
glm(x ~ y, data = data, family = poisson)
Call:
glm(formula = Beg ~ Mass + Species + Mass:Species, family = poisson(link = "log"),
data = cuckoo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.334475 0.227143 1.473 0.14088
Mass 0.094847 0.007261 13.062 < 2e-16 ***
SpeciesWarbler 0.674820 0.259217 2.603 0.00923 **
Mass:SpeciesWarbler -0.021673 0.008389 -2.584 0.00978 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 970.08 on 50 degrees of freedom
Residual deviance: 436.05 on 47 degrees of freedom
AIC: 615.83
Number of Fisher Scoring iterations: 6Note there appears to be a negative interaction effect for Species:Mass, indicating that Begging calls do not increase with mass as much as you would expect for Warblers as compared to Cuckoos.
26.3 Plot the mean regression line for each species:
When we have fitted a model we can use it to generate predictions and see the fit of the regression line (on a log scale)
Plot the mean regression for each species
- Use the emmeans function to generate mean beg rates for different mass + species values
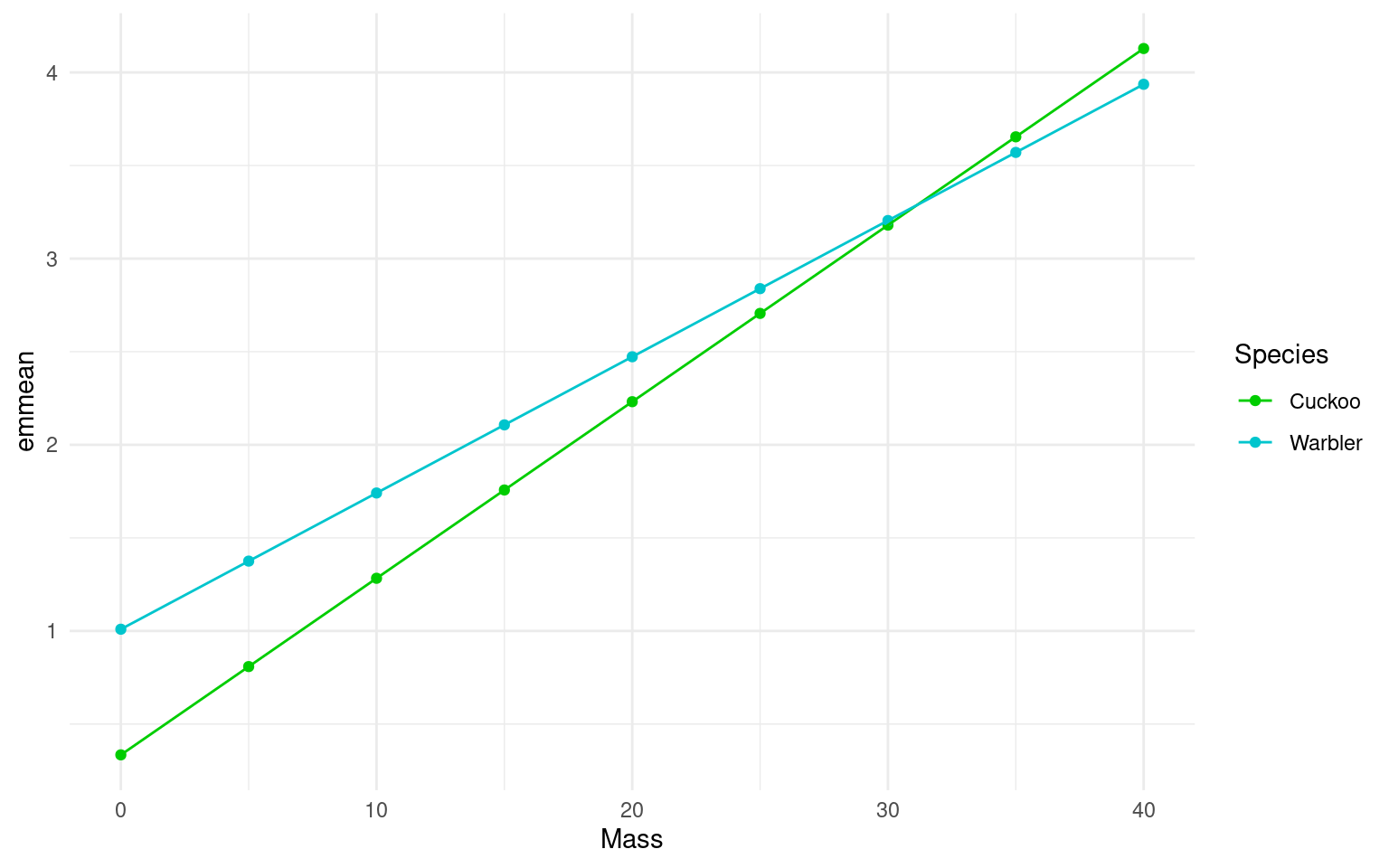
However, it can be more useful to view data on the “response” or “original” scale. Once a model has been fitted we can “back-transform” estimates to produce predicitons on a non-linear response. In this case exponentiating the log-term.
Plot the mean regression for each species on the response scale
Use the
emmeansfunction to generate mean beg rates for different mass + species valuesThis time include the argument
type = "response"Include raw data points as well
Use the help menu if needed
means_response <- emmeans::emmeans(cuckoo_glm1,
specs = ~ Mass + Species + Mass:Species,
at = list(Mass = seq(0,40, by = 5)),
type = "response") |>
as_tibble()
ggplot(data = means_response, aes(x=Mass, y= rate, colour=Species)) +
geom_point(data = cuckoo,
aes(y = Beg,
x = Mass,
colour = Species),
alpha = .4) +
geom_point() +
geom_line()+
scale_colour_manual(values=c("green3","turquoise3"))+
theme_minimal()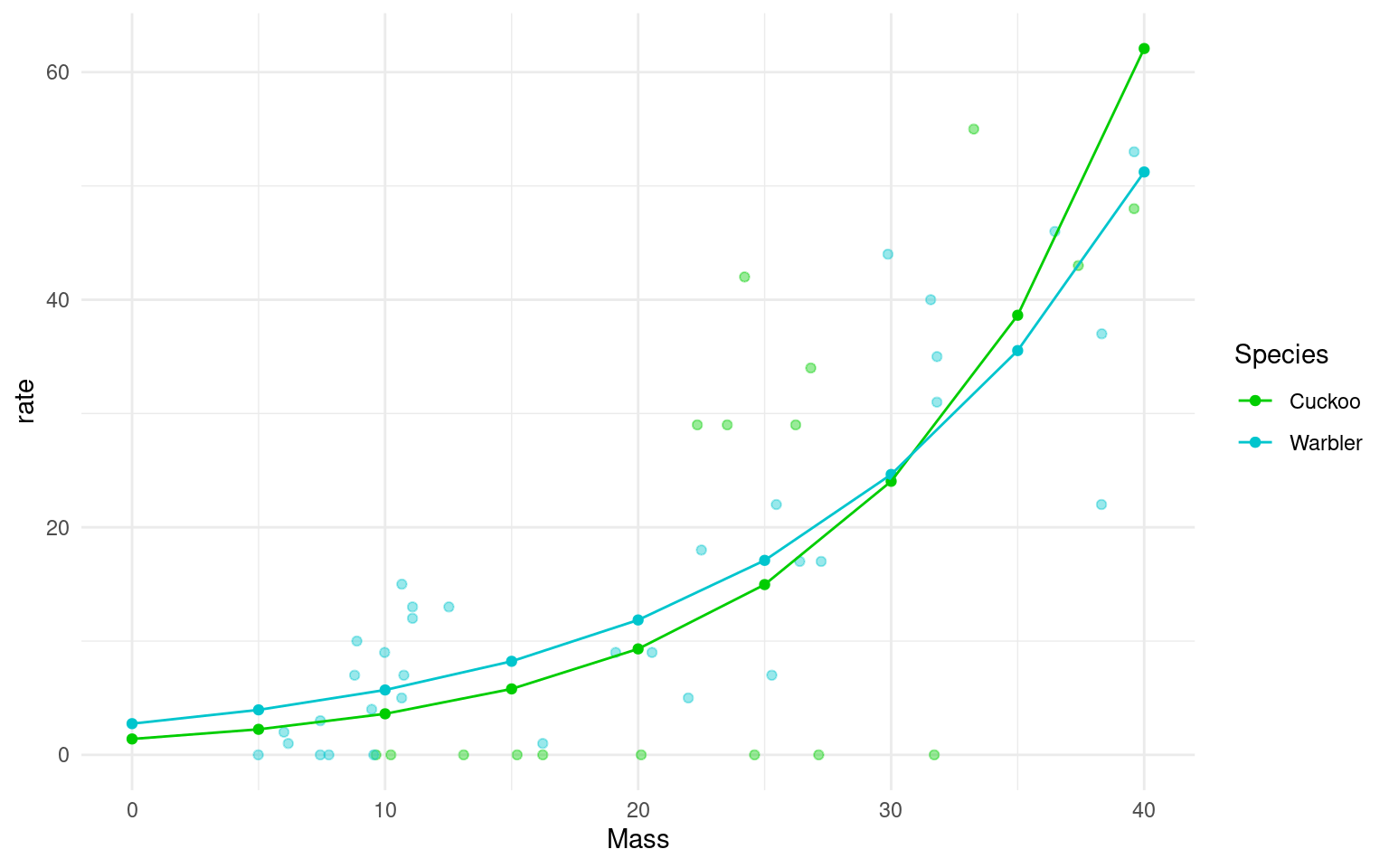
26.3.1 Model checks
Before attempting to interpret our model, we should check that it meets model assumptions and is a good fit for our data. Unlike with OLS linear models, we can only use visual checks - we can no longer carry out checks for normality or heterogeneity as these no longer apply.
Discuss the model fit with a classmate
Does the QQplot show deviance residuals are ok?
How is the homogeneity of variance?
Are there collinearity issues
Are there any influential observations?
Is dispersion appropriate for a Poisson model?
What is the predictive check like?
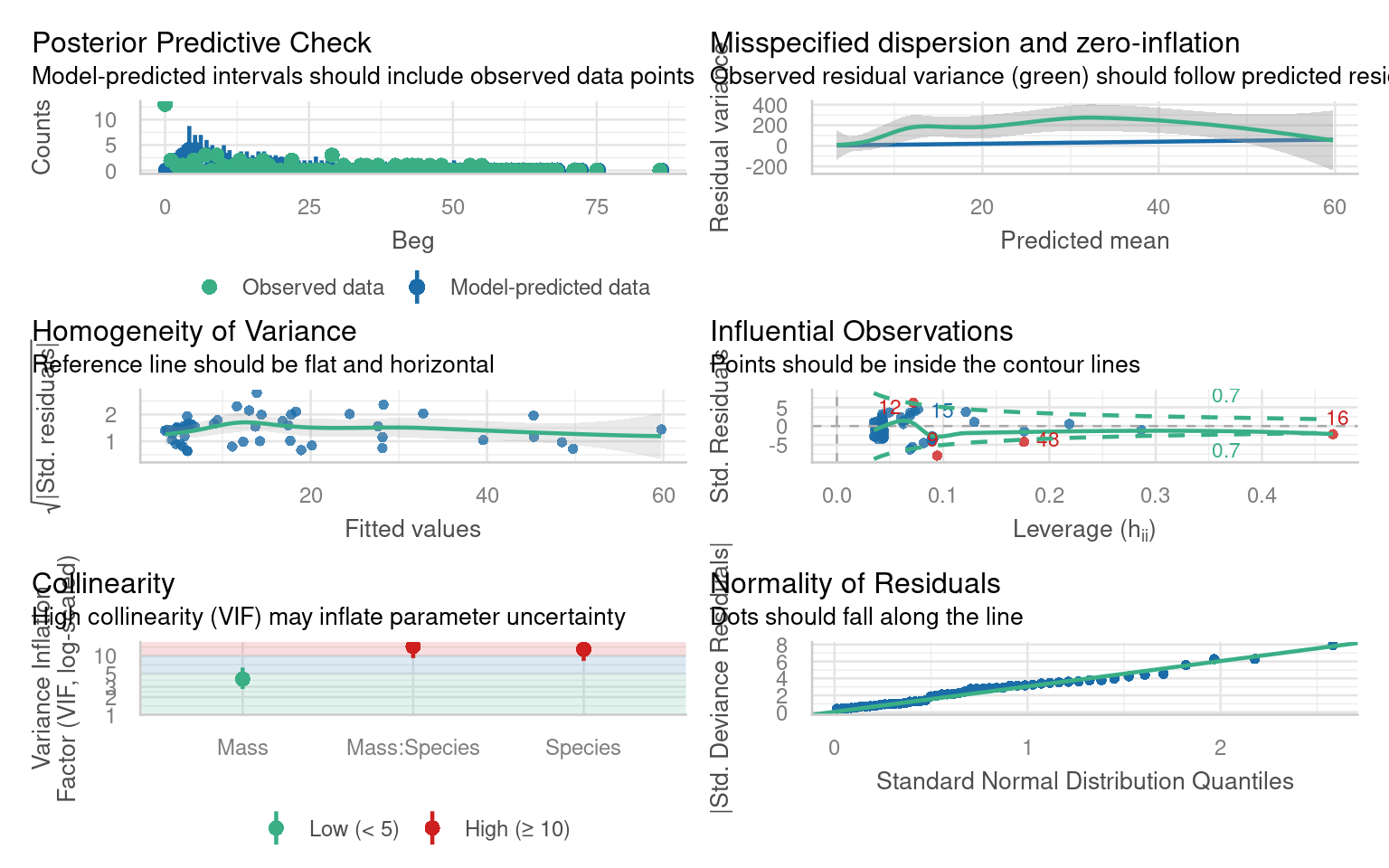
- Does the QQplot show deviance residuals are ok?
The QQplot is standardised “deviance” residuals - these show the residuals appear to fit well with a Poisson distribution
- How is the homogeneity of variance?
The trend line can be misleading, while not perfect there is generally homogeneity - perhaps some clumping at low values
- Are there collinearity issues
Technically yes - but this is because one of our terms is an interaction (a composite of main effects) and can be ignored
- Are there any influential observations?
Yes there are four mildly influential observations - outliers can removed from models and compared to a reduced model to check “sensitivity”. But outliers may resolve themselves if other issues are dealt with
- Is dispersion appropriate for a Poisson model?
This graph is new it looks at observed variance and whether it follows model predictions. This shows that observed variance is generally higher than predicted by the model. This may indicate our model has “overdispersion”.
- What is the predictive check like?
Generally good - but the model appears to underpredict zeroes.
26.3.2 Model Summary
Call:
glm(formula = Beg ~ Mass + Species + Mass:Species, family = poisson(link = "log"),
data = cuckoo)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.334475 0.227143 1.473 0.14088
Mass 0.094847 0.007261 13.062 < 2e-16 ***
SpeciesWarbler 0.674820 0.259217 2.603 0.00923 **
Mass:SpeciesWarbler -0.021673 0.008389 -2.584 0.00978 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 970.08 on 50 degrees of freedom
Residual deviance: 436.05 on 47 degrees of freedom
AIC: 615.83
Number of Fisher Scoring iterations: 6A reminder of how to interpret the regression coefficients of a model with an interaction term
Intercept = \(\beta 0\) (intercept for the reference or baseline so here the log of the mean number of begging calls for cuckoos when mass is 0)
Mass = \(\beta1\) (slope: the change in the log mean count of begging calls for every gram of bodyweight for cuckoos)
SpeciesWarbler = \(\beta2\) (the log mean increase/decrease in begging call rate of the warblers relative to cuckoos)
Mass:SpeciesWarbler =\(\beta3\) (the log mean increase/decrease in the slope for warblers relative to cuckoos)
Note
Because this is a Poisson distribution where variance is fixed with the mean we are using z scores. Estimates are on a log scale because of the link function - this means so are any S.E. or confidence intervals
Luckily when you tidy your models up with broom you can specify that you want to put model predictions on the response variable scale by specifying exponentiate = T which will remove the log transformation, and allow easy calculation of confidence intervals.
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 1.3972071 | 0.2271431 | 1.472531 | 0.1408775 | 0.8858795 | 2.1589962 |
| Mass | 1.0994905 | 0.0072615 | 13.061667 | 0.0000000 | 1.0841087 | 1.1154266 |
| SpeciesWarbler | 1.9636787 | 0.2592166 | 2.603304 | 0.0092330 | 1.1889064 | 3.2864493 |
| Mass:SpeciesWarbler | 0.9785598 | 0.0083890 | -2.583559 | 0.0097787 | 0.9625068 | 0.9946969 |
26.3.3 Interpretation
It is very important to remember whether you are describing the results on the log-link scale or the original scale. It would usually make more sense to provide answers on the original scale, but this means you must first exponentiate the relationship between response predictors as described above when writing the results.
Warning
The default coefficients from the model summary are on a log scale, and are additive as such these can be added and subtracted from each other (just like ordinary least squares regression) to work out log-estimates. BUT if you exponentiate the terms of the model you get values on the ‘response’ scale, but these are now changes in ‘rate’ and are multiplicative.
Also remember that as Poisson models have ‘fixed variance’ z- and Chisquare distributions are used instead of t- and F.
In this example we wished to infer the relationship between begging rates and mass in these two species.
I hypothesised that the rate of begging in chicks would increase as their body size increased. Interestingly I found there was a significant interaction effect with mass and species, where Warbler chicks increased their calling rate with mass at a rate that was only 0.98 [95%CI: 0.96-0.99] that of Cuckoo chicks (Poisson GLM: \(\chi^2\)1,47 = 6.77, P = 0.009). This meant that while at hatching Warbler chicks start with a mean call rate that is higher than their parasitic brood mates, this quickly reverses as they grow.
# For a fixed mean-variance model we use a Chisquare distribution
drop1(cuckoo_glm1, test = "Chisq")
# emmeans can be another handy function - if you specify response then here it provideds the average call rate for each species, at the average value for any continuous measures - so here the average call rate for both species at an average body mass of 20.3
emmeans::emmeans(cuckoo_glm1, specs = ~ Species:Mass, type = "response")| Df | Deviance | AIC | LRT | Pr(>Chi) | |
|---|---|---|---|---|---|
| NA | 436.0458 | 615.8282 | NA | NA | |
| Mass:Species | 1 | 442.8118 | 620.5942 | 6.765991 | 0.0092911 |
Species Mass rate SE df asymp.LCL asymp.UCL
Cuckoo 20.3 9.61 0.884 Inf 8.03 11.5
Warbler 20.3 12.15 0.658 Inf 10.93 13.5
Confidence level used: 0.95
Intervals are back-transformed from the log scale 26.4 Overdispersion
There is one extra check we need to apply to a Poisson model and that’s for overdispersion
Poisson (and binomial models) assume that the variance is equal to the mean.
Count data often violate the strict Poisson assumption of equal mean and variance. The negative binomial model allows extra variability (“overdispersion”) via an additional dispersion parameter.
If there is residual deviance that is bigger than the residual degrees of freedom then there is more variance than we expect from the prediction of the mean by our model.
Overdispersion in Poisson models can be diagnosed by:
\[ \hat\phi = \frac{\text{Residual Deviance}}{\text{Residual Degrees of Freedom}} \]
Overdispersion statistic values > 1 = Overdispersed
Overdispersion is a result of larger than expected variance for that mean under a Poisson distribution, this is clearly an issue with our model!
| Value of 𝜙̂ | Interpretation |
|---|---|
| ≈ 1 | Good fit — variance consistent with Poisson assumption. |
| 2 to 4 | Moderate overdispersion — Quasipoisson. |
| > 4 (e.g., 6–8.7) | Severe overdispersion — observed variability far exceeds Poisson expectation - Negative Binomial. |
Model checks that helped indicate this would be an issue was the “Misspecified dispersion” plot. We can also check whether this misspecified dispersion meets a formal threshold for overdispersion with a function:
# Overdispersion test
dispersion ratio = 7.724
Pearson's Chi-Squared = 363.036
p-value = < 0.00126.4.1 Minor overdispersion 2-4
Luckily a simple fix is to fit a quasi-likelihood model which accounts for this, think of “quasi” as “sort of but not completely” Poisson.
Call:
glm(formula = Beg ~ Mass + Species + Mass:Species, family = quasipoisson(link = "log"),
data = cuckoo)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.33448 0.63129 0.530 0.599
Mass 0.09485 0.02018 4.700 2.3e-05 ***
SpeciesWarbler 0.67482 0.72043 0.937 0.354
Mass:SpeciesWarbler -0.02167 0.02332 -0.930 0.357
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for quasipoisson family taken to be 7.7242)
Null deviance: 970.08 on 50 degrees of freedom
Residual deviance: 436.05 on 47 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 6Compare this to the first glm - Dispersion parameter was 1. (Mean and variance are assumed to be identical). Here the dispersion parameter is what? This parameter indicates by how much more variance increases over the mean.
As you can see, while none of the estimates have changed, the standard errors (and therefore our confidence intervals) have, this accounts for the greater than expected uncertainty we saw with the deviance, and applies a more cautious estimate of uncertainty. The interaction effect appears to no longer be significant at \(\alpha\) = 0.05, now that we have wider standard errors.
Warning
Because we are now estimating the variance again, the test statistics have reverted to t distributions and anova and drop1 functions should specify the F-test again.
26.4.2 Severe overdispersion > 4
The initial Poisson model likely showed evidence of overdispersion (variance much greater than the mean). Using a negative binomial (glm.nb) allows the dispersion parameter to be estimated from the data rather than fixed at 1, providing a better fit when count variability is high.
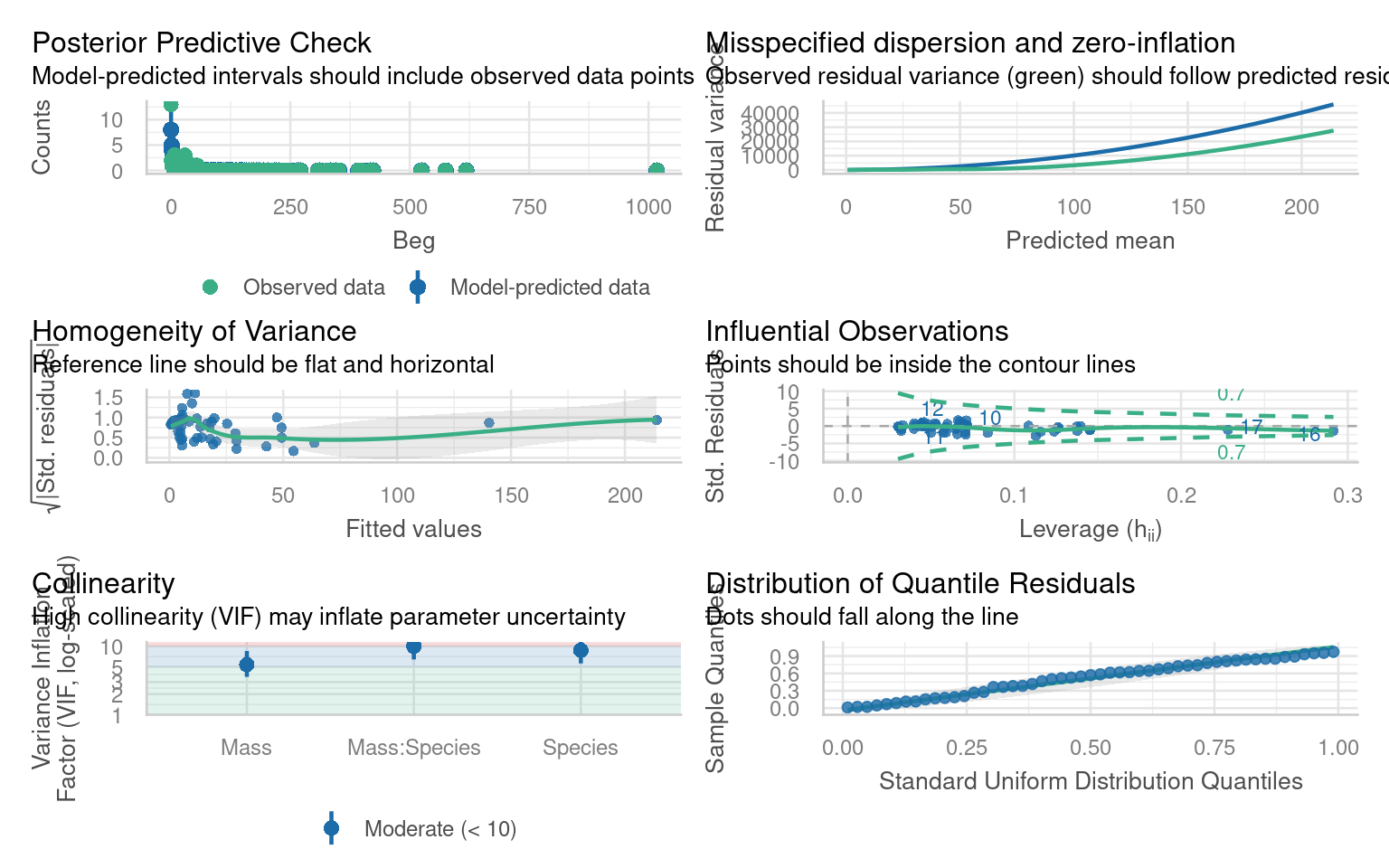
26.5 Zero inflation
Look at the negative binomial model checks - in particular the Posterior Predictive Check. Are there any issues with the observations against predictions?
The zero-inflated Poisson (ZIP) allows some zeros to arise from a separate “structural zero” process. ziformula = ~1 specifies a constant zero-inflation probability across observations.
This can be an alternate source of overdispersion:
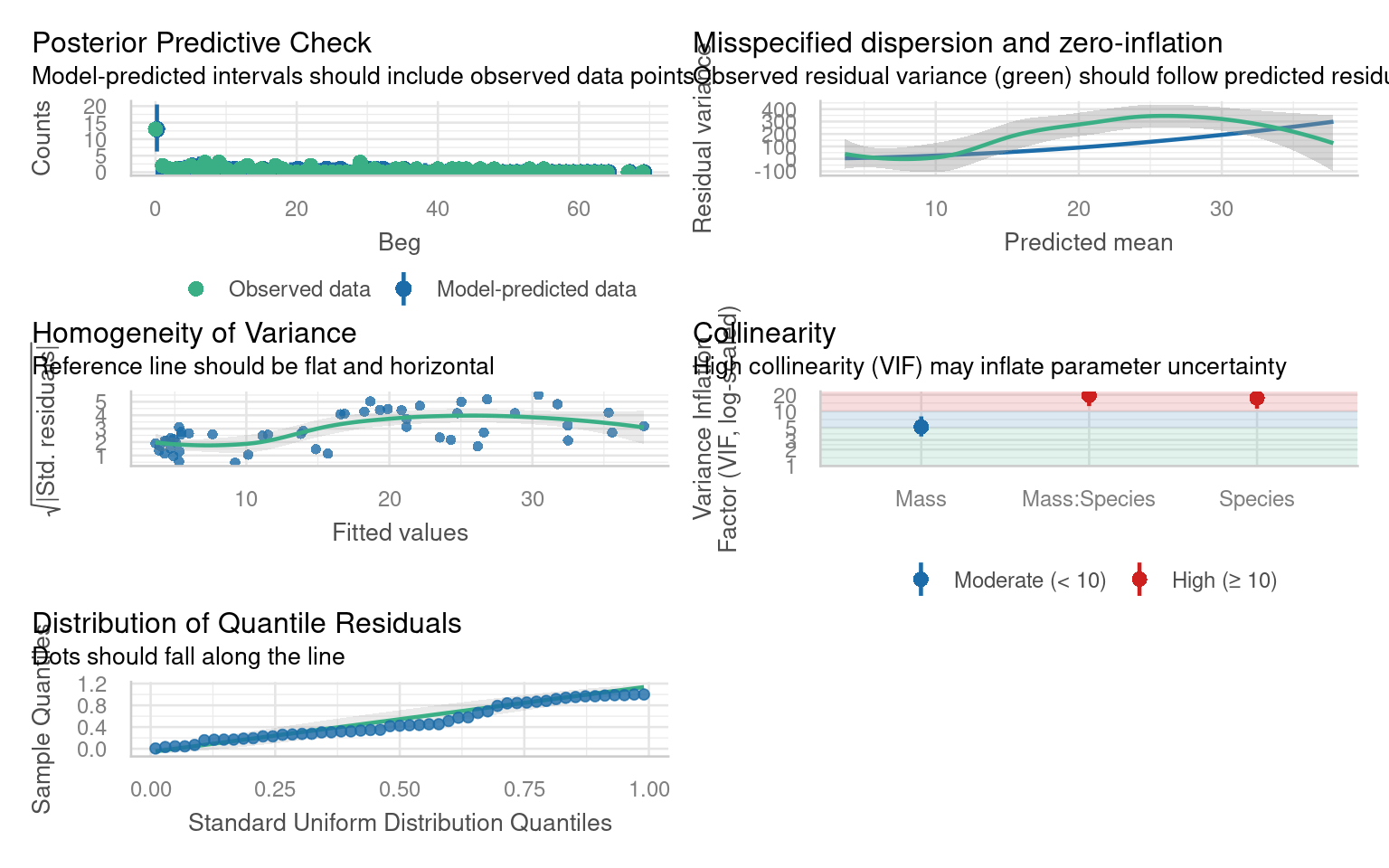
26.5.1 Compare models
Compare AICs of the cuckoo_negbin and cuckoo_zip
If overdispersion persists even with ZIP, it may reflect unmodeled heterogeneity rather than purely excess zeros and we can try a zero-inflated negative binomial model
Make and compare a zero-inflated negative binomial
Swap family =
poissonfornbinom
26.5.2 Modelling a pattern in the zeroes
Suppose inspection of residuals or exploratory plots suggests that zeros occur more often in some species or at particular mass ranges.
So far a zinb model has produced the best model fit and AIC values. But we have assumed a constant and equal probability of generating zeroes throughout our data.
What it is: A statistical method for model selection that estimates the prediction error and relative quality of different statistical models for a given dataset.
How it works: It provides a single numerical score that estimates the amount of information lost by a model. It balances the goodness of fit (how well the model fits the data) with the model’s complexity (number of parameters).
How to use it: When comparing multiple models on the same data and with the same dependent variable, the one with the lowest AIC score is preferred because it is considered the best relative fit for the data
What if zeroes are related to our predictors?
Question
- What formula might you provide to a zero inflated model to get better predictions?
cuckoo_zip2 <- glmmTMB::glmmTMB(Beg ~ Mass+Species+Mass:Species, family = poisson, ziformula= ~Mass:Species, data=cuckoo)
cuckoo_zinb2 <- glmmTMB::glmmTMB(Beg ~ Mass+Species+Mass:Species, family = nbinom1, ziformula= ~Mass:Species, data=cuckoo)
AIC(cuckoo_zip, cuckoo_zip2, cuckoo_zinb, cuckoo_zinb2)| df | AIC | |
|---|---|---|
| cuckoo_zip | 5 | 347.8592 |
| cuckoo_zip2 | 7 | 325.4841 |
| cuckoo_zinb | 6 | 320.5512 |
| cuckoo_zinb2 | 8 | 298.4325 |
Zero inflated negbin model beats zero inflated poisson model on AIC alone.
But the negbin variance shape is mis-matched, the data does not increase with variance as quickly as predicted by the negbin model.
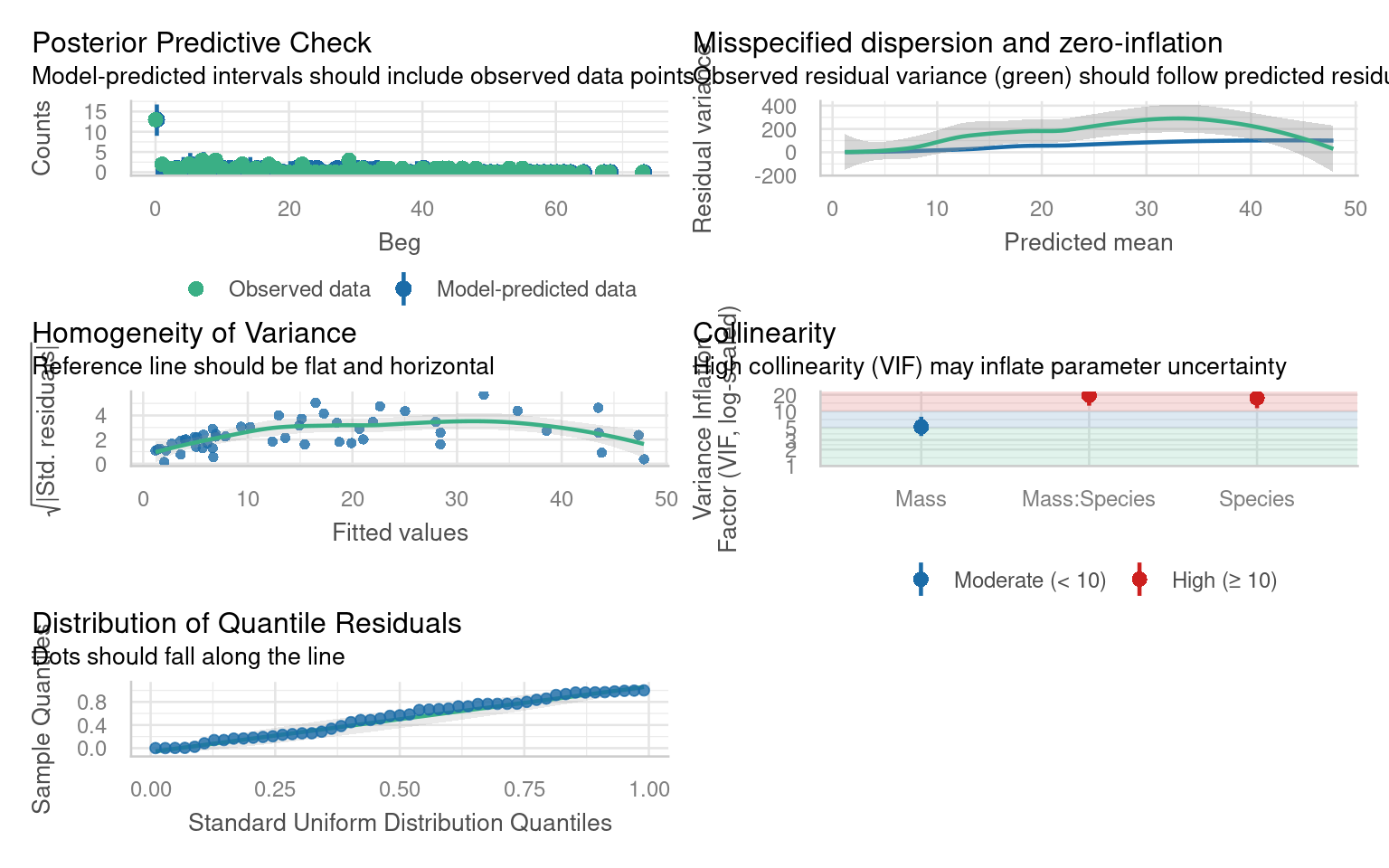
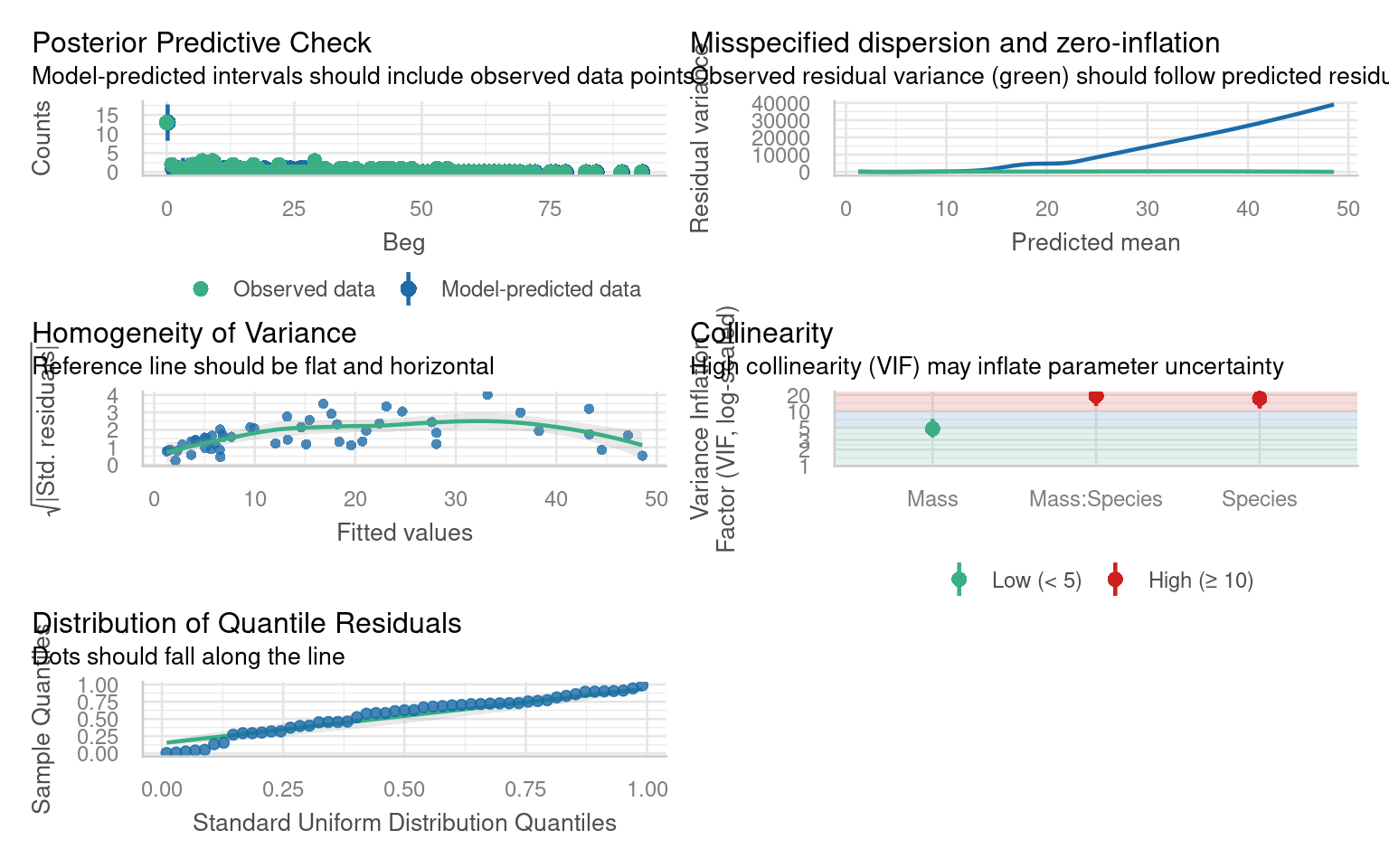
26.6 Summary
Begin by fitting a Poisson GLM to model count data (e.g., begging calls) using a log link, then inspect diagnostic plots to assess residuals, variance homogeneity, and dispersion.
If the model shows overdispersion (variance > mean), refit using a quasipoisson or negative binomial model to account for excess variability.
Examine model adequacy with
check_model()and test for zero inflation; if extra zeros exist, fit zero-inflated Poisson or zero-inflated negative binomial models withglmmTMB.Compare model fits using AIC and, if needed, include predictors in the zero-inflation component to capture structured patterns in zero counts.