18 Linear models
In the last chapter we conducted a simple analysis of Darwin’s maize data using R. We worked out confidence intervals ‘by hand’. This simple method allowed us to learn more about analysis, estimates, standard error and confidence. But it is also slow, and it relied on the assumptions of a z-distribution to assess true differences between the groups.
We will now work through a much more efficient way to carry out comparisons, we will use the functions in R that let us perform a linear model analysis.
18.0.1 Packages
18.1 A linear model analysis for calculating means
R has a general function lm() for fitting linear models, this is part of base R (does not require the tidyverse packages). We will run through a few different iterations of the linear model increasing in complexity. We will often want to fit several models to our data, so a common way to work is to fit a model and assign it to a named R object, so that we can extract data from when we need it.
In the example below I have called the model lsmodel0, short for “least-squares model 0”, this is because the linear-model uses a technique called least squares.
The first argument of the lm() function is formula (we won’t write this out in full in the future) - and this specifies we want to analyse a response variable (height) as a function of an explanatory variable using the tilde symbol (~).
The simplest possible model ignores any explanatory variables, instead the 1 indicates we just want to estimate an intercept.
Without explanatory variables this means the formula will just estimate the overall mean height of all the plants in the dataset.
18.2 Summaries for models
When you have made a linear model, we can investigate a summary of the model using the base R function summary(). There is also a tidyverse option provided by the package broom(Robinson et al. (2025)).
18.2.1 Model summary
Call:
lm(formula = height ~ 1, data = darwin)
Residuals:
Min 1Q Median 3Q Max
-6.8833 -1.3521 -0.0083 2.4917 4.6167
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 18.8833 0.5808 32.52 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.181 on 29 degrees of freedomThe output above is called the table of coefficients. The 18.9 is the estimate of the model coefficient (in this case it is the overall mean), together with its standard error (SEM). The first row in any R model output is always labelled the ‘Intercept’ and the challenge is usually to workout what that represents. In this case we can prove that this is the same as the overall mean as follows:
This simple model allows us to understand what the lm() function does.
18.2.2 Compare means
What we really want is a linear model that analyses the difference in average plant height (type) as a function of pollination type. We can use the lm() function to fit this as a linear model as follows:
Call:
lm(formula = height ~ type, data = darwin)
Residuals:
Min 1Q Median 3Q Max
-8.1917 -1.0729 0.8042 1.9021 3.3083
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.1917 0.7592 26.596 <2e-16 ***
typeSelf -2.6167 1.0737 -2.437 0.0214 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.94 on 28 degrees of freedom
Multiple R-squared: 0.175, Adjusted R-squared: 0.1455
F-statistic: 5.94 on 1 and 28 DF, p-value: 0.02141Now the model formula contains the pollination type in addition to an intercept.
18.2.3 Coefficients
This is where the model results are reported.
Intercept: This is the predicted height when the plant type is “Cross” fertilised, which is the reference category). The estimate is 20.1917, which means the average height for plants that are not self-fertilised is about 20.19 inches.
typeSelf: This coefficient tells us how the height of “Self” fertilized plants differs from the reference group (“Cross” fertilized plants). The estimate is -2.6167, meaning “Self” fertilized plants are, on average, 2.62 units shorter than “Cross” fertilized plants.
The Std. Error for each coefficient measures the uncertainty in the estimate. Smaller values indicate more precise estimates. For example, the standard error of 1.0737 for the “typeSelf” coefficient suggests there’s some variability in how much shorter the “Self” fertilized plants are, but it’s reasonably precise.
The t value is the ratio of the estimate to its standard error (\(\frac{Mean}{Std. Error}\)). The larger the t-value (either positive or negative), the more evidence there is that the estimate is different from zero.
Pr(>|t|) gives the p-value, which tells us the probability of observing a result as extreme as this, assuming that there is no real effect (i.e., the null hypothesis is true). In this case, a p-value of 0.0214 means there’s about a 2% chance that the difference in height between “Self” and “Cross” fertilized plants is due to random chance. Since this is below the typical cutoff of 0.05, it suggests that the difference is statistically significant.
Significance codes: These symbols next to the p-value indicate how strong the evidence is. In this case, one star (*) indicates a p-value below 0.05, meaning the effect is considered statistically significant.

The t-statistic is closely related to the z-statistic but is used in significance testing when the sample size is small or the population standard deviation is unknown. As we almost never know the “population” standard deviation, it is always safer to use the t-distribution for significance tests.
18.2.4 The t-Distribution:
The t-distribution is similar to the normal distribution but has more spread (wider tails), especially with smaller sample sizes. As the sample size increases, the t-distribution approaches the normal distribution.
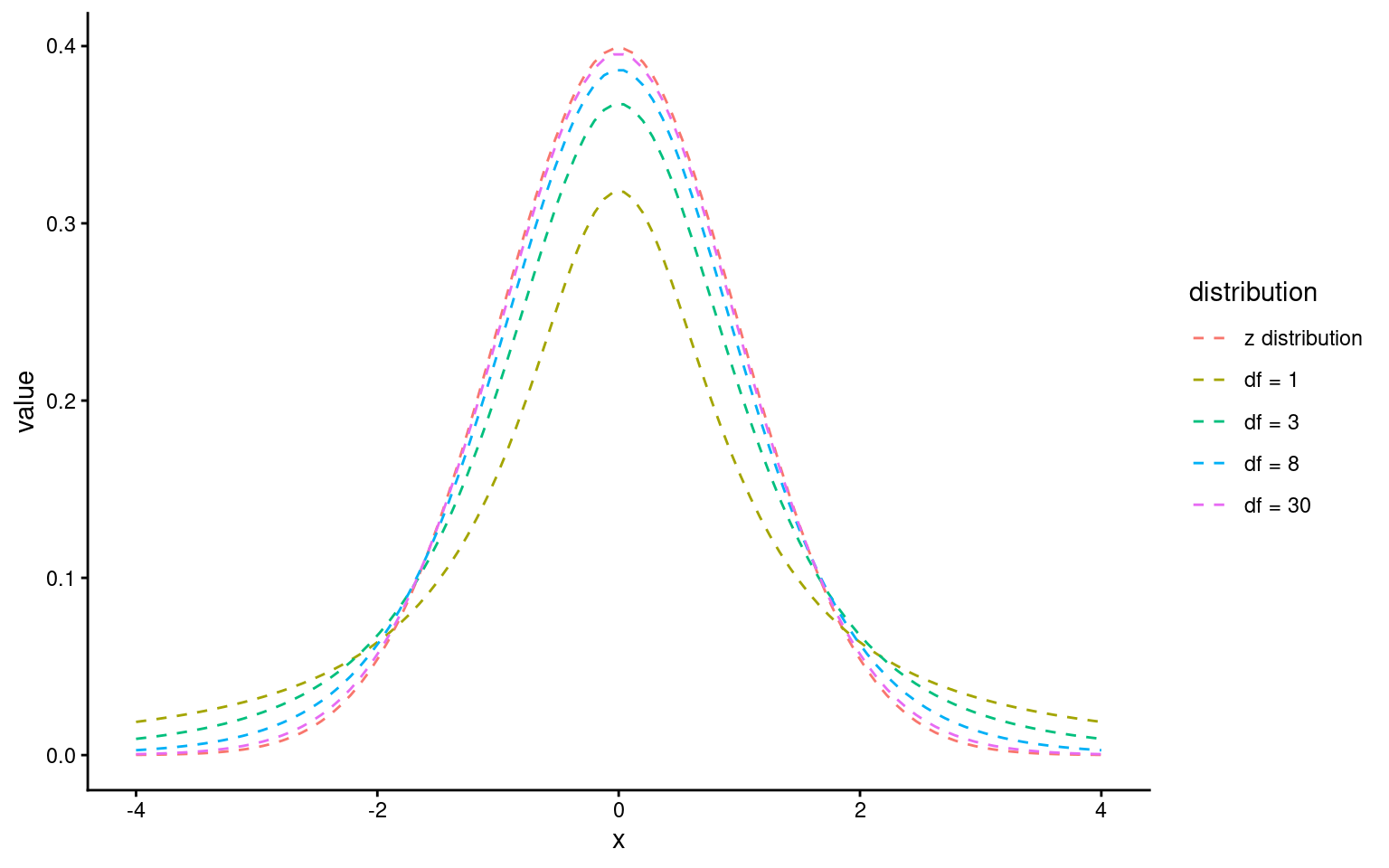
18.3 Assumptions: minimal, practical checks
When we fit a linear model for a two-group comparison, we need to check whether the numbers we have generated are reliable by checking the fit of our model against some assumptions:
- Normality: The t-test and lm are fairly robust for moderate sample sizes. A quick check is still useful.
The normality assumption mainly affects standard errors, confidence intervals, and p-values.
For moderate sample sizes, small deviations from normality are rarely problematic.
- Equal variances: In two-group comparisons, unequal variances are common and not automatically a concern. What matters is whether the difference in variability is large enough to distort uncertainty estimates.
Unequal variances do not bias the estimated means or their difference.
They can, however, affect standard errors and therefore inference.
Making these checks is simple and quick with performance::check_model()
# -------------------------------------------------------------------
# Check the NORMALITY of residuals for the linear model 'lsmodel1'
# -------------------------------------------------------------------
# Purpose:
# - In linear regression, residuals should ideally be normally distributed.
# This affects the validity of confidence intervals and p-values.
normality <- check_normality(lsmodel1)
# Visualize the normality check with a Q–Q plot (quantile–quantile plot).
#
# The plot() method for the object returned by 'check_normality()' creates:
# - A Q–Q plot comparing the quantiles of the residuals
# against the theoretical quantiles from a normal distribution.
# - The line represents the "ideal" normal distribution.
# Argument:
# detrend = FALSE → Shows the standard Q–Q plot (not detrended).
# If TRUE, it shows the residuals from the Q–Q line (useful for subtle deviations).
#
# Interpretation:
# - We look for large, systematic departures from the diagonal line
plot(normality, detrend = FALSE)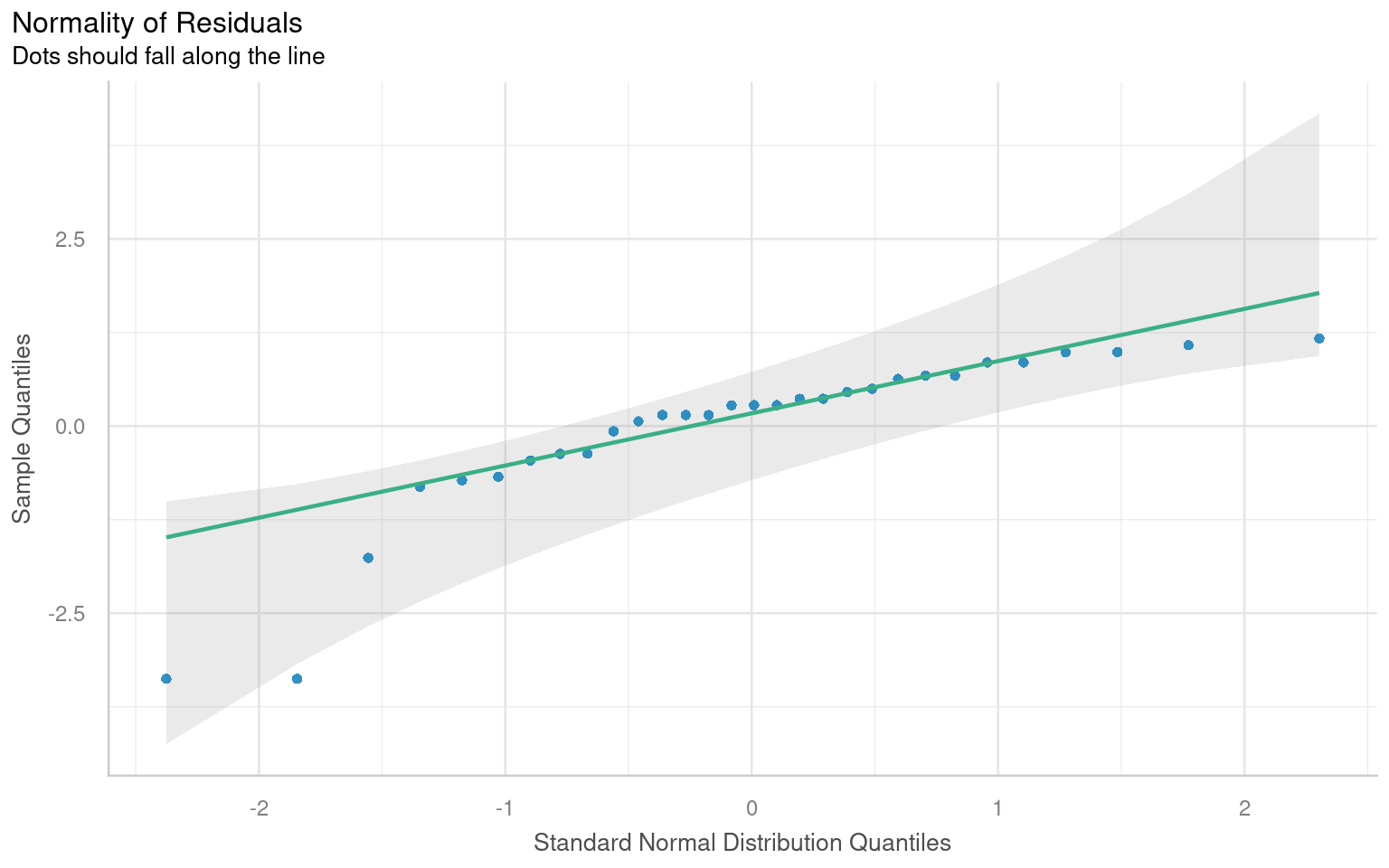
# -------------------------------------------------------------------
# Check for HETEROSCEDASTICITY (unequal variances of residuals)
# -------------------------------------------------------------------
# The function 'check_heteroscedasticity()' tests whether the residuals
# from the model have constant variance (homoscedasticity).
#
# Under the hood, it typically performs:
# - Breusch–Pagan test (default)
#
# Purpose:
# - In linear regression, we assume the variance of residuals is constant
# across fitted values (homoscedasticity).
# - Heteroscedasticity can bias standard errors and affect inference.
heteroscedasticity <- check_heteroscedasticity(lsmodel1)
# Visualize the results with a residuals-vs-fitted plot.
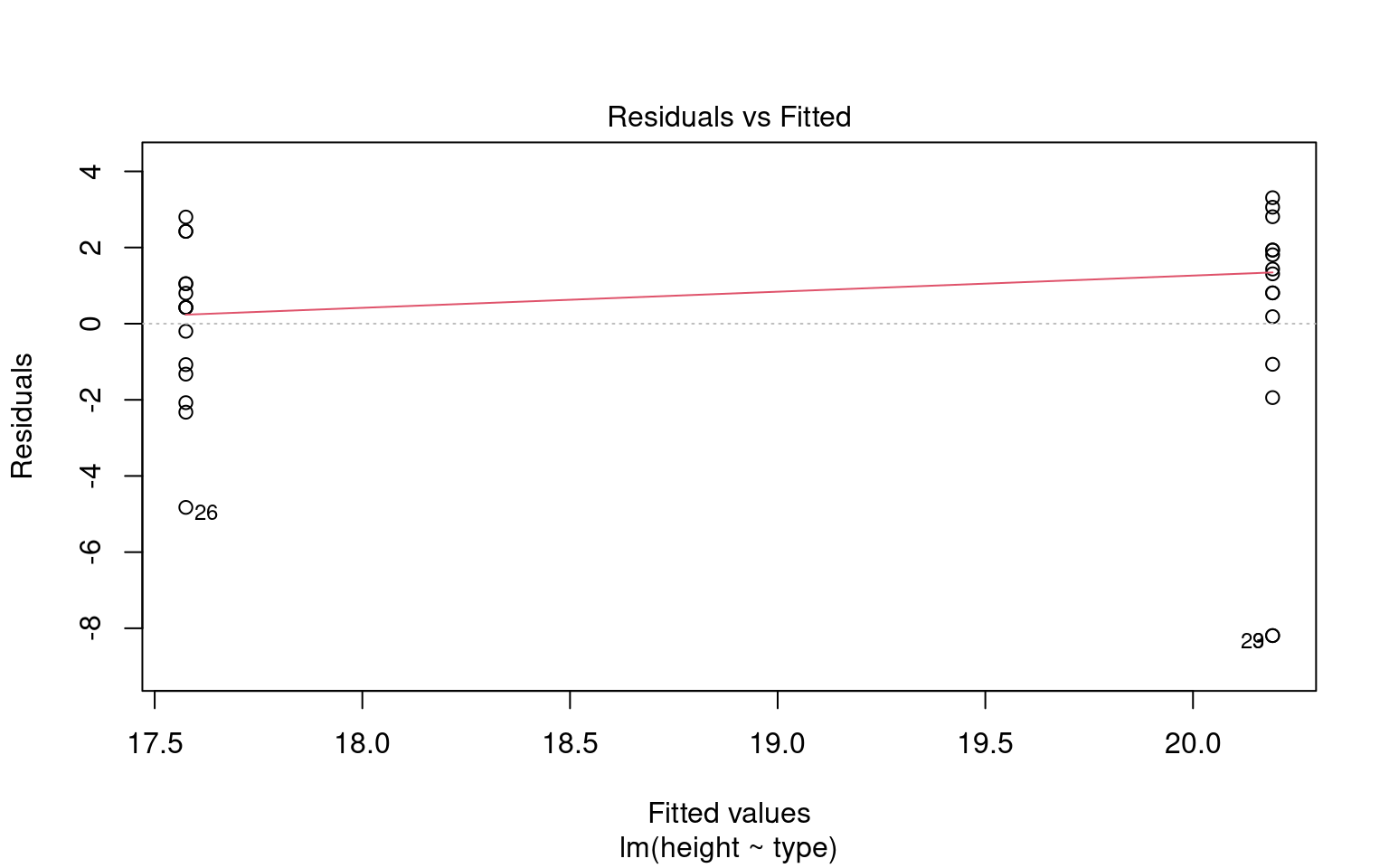
# The plot() method for 'check_heteroscedasticity()' creates:
# - A scatterplot of fitted values (x-axis) vs. residuals (y-axis)
# - A smoothing line (usually loess) that helps detect trends.
#
# Interpretation:
# - Residuals versus fitted values plot.
# A roughly constant spread suggests the assumption is reasonable;
# strong patterns or funnel shapes suggest heteroscedasticity.
plot(heteroscedasticity)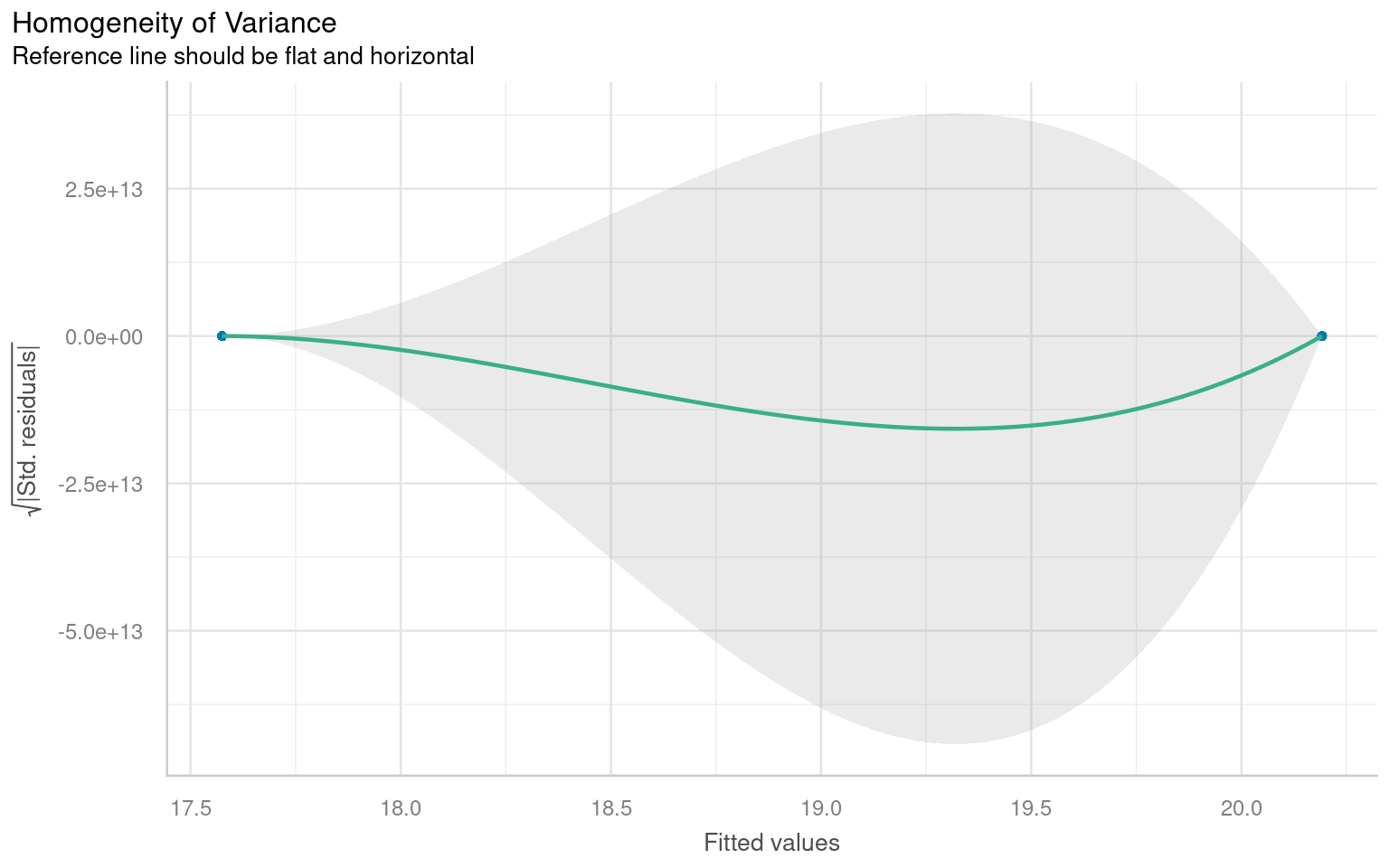
We don’t have to use performance, base R can visualise these with the plot() function
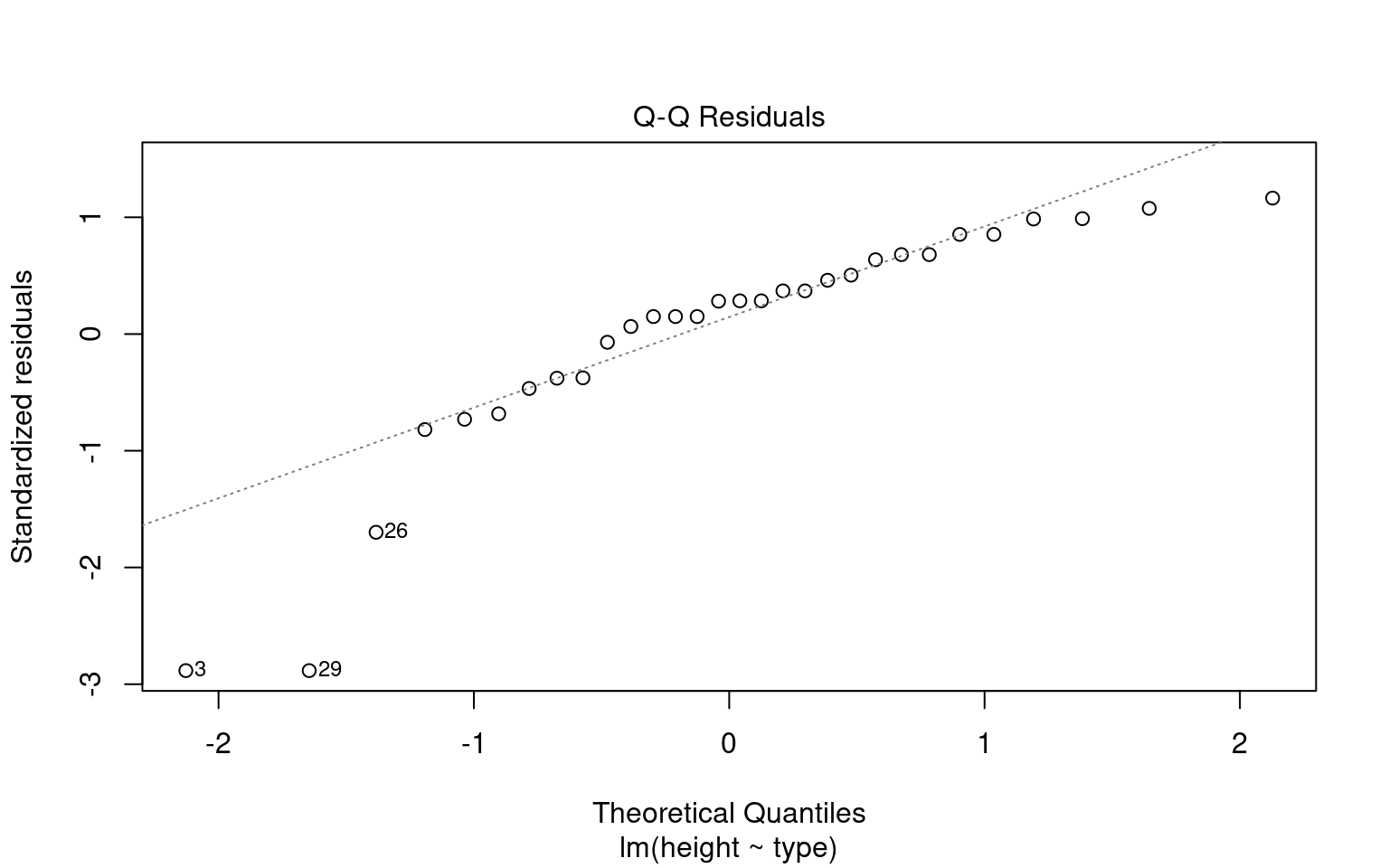
18.3.1 A simple write up
Once we have satisfied ourselves that there are no severe violations of model assumptions, we proceed to interpret the fitted model.
From this summary model we can make conclusions about the effect of inbreeding and produce a simple write up:
“The maize plants that have been cross pollinated had an average height (mean ±S.E.) of 20.19 (± 0.76) inches and were taller on average than the self-pollinated plants, with a mean difference in height of 2.62 (±1.07) inches (t(28) = -2.44, p = 0.02)”
18.4 Confidence intervals
A confidence interval is a range of values that we expect to contain the true population parameter (like a mean or difference in means) with a certain level of confidence. In the case of a 95% confidence interval, this means we are 95% confident that the true parameter lies within the interval.
The confidence interval is closely tied to the standard error (SE), which measures how much variability we expect in the sample estimates due to sampling randomness. The standard error depends on the sample size and the variability in the data, and it’s computed as:
\[ Standard~Error(SE)= \frac{SD}{\sqrt(n)} \] For a 95% confidence interval, we use the t-distribution to determine how many standard errors away from the sample estimate we should go to capture the true population parameter with 95% confidence. In most cases:
\[ Confidence~Interval=Mean(\pm(criticial~t) \times SE) \] Where:
critical t = is the critical value from the t-distribution that corresponds to a 95% confidence level
Standard Error - the precision of the sample estimate
18.4.1 Confidence intervals and p-values
A p-value and a confidence interval are inversely related, but they provide information in different ways:
A p-value tells you how likely it is to observe your data (or something more extreme) if the null hypothesis is true. It’s a single number that quantifies the evidence against the null hypothesis. If the p-value is less than the significance level (typically 0.05), you reject the null hypothesis.
A confidence interval provides a range of plausible values for the true parameter. If the confidence interval does not include 0 (or another hypothesized value, such as a difference of 0 between two groups), it suggests the parameter is significantly different from 0 at the corresponding confidence level (usually 95%).
Here’s how they are inversely related:
p-value < 0.05: If the p-value is below 0.05, this typically means the null hypothesis (no effect or no difference) is rejected, suggesting a statistically significant result. In this case, a 95% confidence interval for the effect will not include 0, indicating the result is statistically significant.
p-value > 0.05: If the p-value is greater than 0.05, this means we do not reject the null hypothesis. In this scenario, the 95% confidence interval will likely include 0, indicating that the true effect could be zero and the result is not statistically significant.
18.4.2 Confidence intervals (CI) in R
With a wrapper function around our model we can generate accurate 95% confidence intervals from the SE and calculated t-distribution:
Because this follows the same layout as the table of coefficients, the output intercept row gives a 95% CI for the height of the crossed plants and the second row gives a 95% interval for the difference in height between crossed and selfed plants. The lower and upper bounds are the 2.5% and 97.5% of a t-distribution.
It is this difference in height in which we are specifically interested.
18.4.3 Answering the question
Darwin’s original hypothesis was that self-pollination would reduce fitness (using height as a proxy for this). The null hypothesis is that there is no effect of pollination type, and therefore no difference in the average heights.
We must ask ourselves if our experiment is consistent with this null hypothesis or can we reject it? If we choose to reject the null hypothesis, with what level of confidence can we do so?
To do this, we can simply determine whether or not the predicted value of our null hypothesis (a difference of zero) lies inside the 95% CI for the difference of the mean.
If our confidence intervals contain zero (or no difference), then we cannot establish a difference between our sample difference in height (-2.62 inches) from the null prediction of zero difference, given the level of variability (noise) in our data.
In this case we can see that the upper and lower bounds of the confidence intervals do not contain zero. The difference in height is consistent with Darwin’s alternate hypothesis of inbreeding depression.
18.4.4 Plausible range of significant difference
A 95% CI provides a range of values where the true effect (like a difference between two group means) is likely to fall. Our analysis suggests that within the 95% confidence interval the true (population) difference could be between 0.42 and 4.8 inches in height difference between crossed and selfed plants.
Minimum effect size: the value closest to zero gives a sense of the minimum effect size that is plausible at 95% confidence. This is important because it shows the smallest effect you might expect. Here the minimum effect size is 0.42 inches. Or that the cost of inbreeding could be as little as a 0.42 inch height difference.
The GGally package has a handy ggcoef_model() function, that produces a graph of the estimated mean difference with an approx 95% CI. As we can see we are able to reject the null hypothesis at a 95% confidence level.
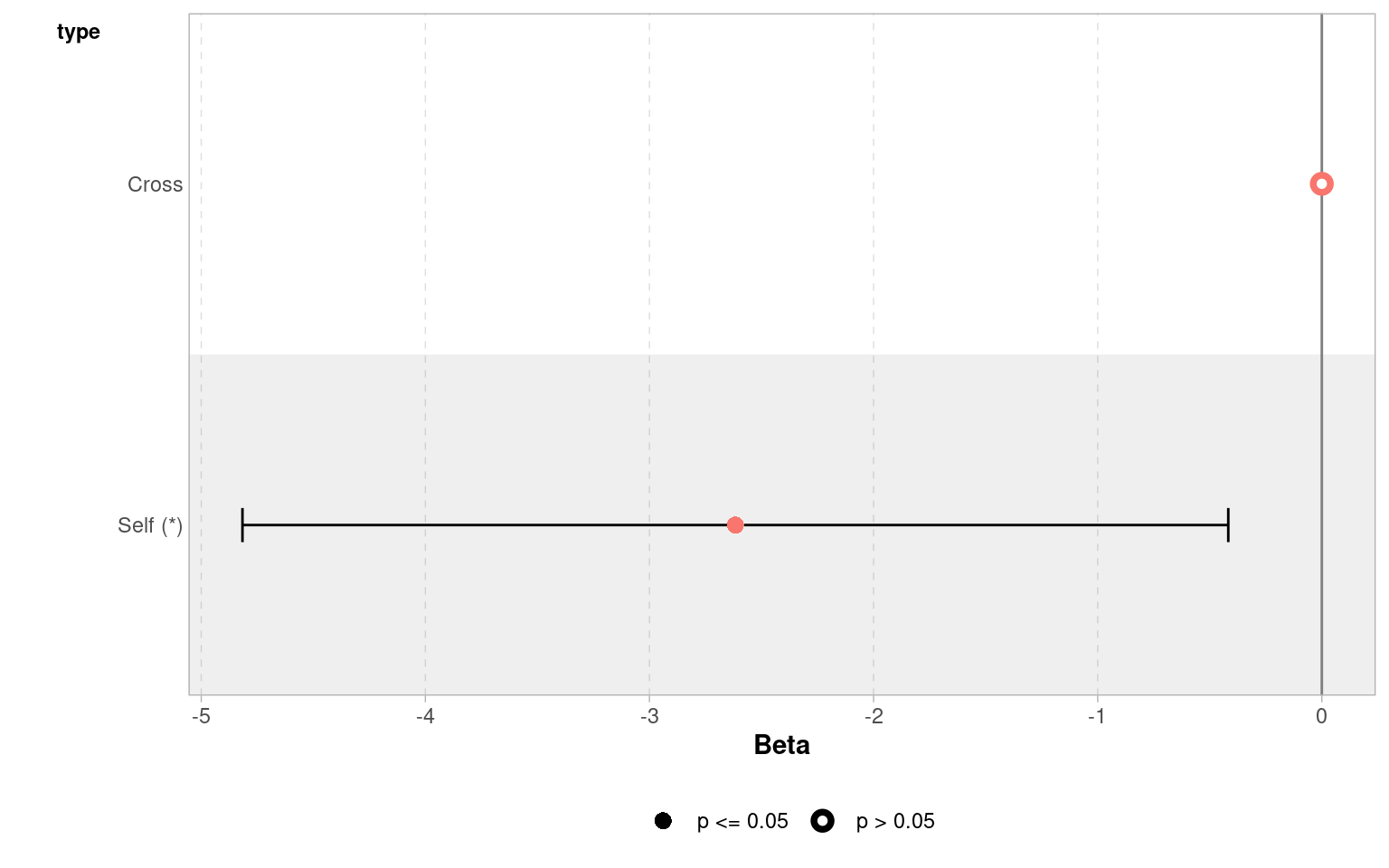
Set the confidence levels to 99%, do you think the difference between treatments is still statistically significant at an of 0.01?
If we increase the level of confidence (from 95% to 99%, roughly 2 SE to 3 SE), then we may find that we cannot reject the null hypothesis at a higher threshold of confidence (p < 0.01). Try altering the conf.level argument above for yourself to see this in action.
We can also include this argument in the tidy() function if we wish to:
18.5 Estimating means
One limitation of the table of coefficients output is that it doesn’t provide the mean and standard error of the other treatment level (only the difference between them). If we wish to calculate the “other” mean and SE then we can get R to do this.
18.5.1 Changing the intercept
One way to do this is to change the levels of the type variable as a factor:
# Perform linear regression on darwin data with Self as the intercept
darwin |>
# Convert 'type' column to a factor
mutate(type = factor(type)) |>
# Relevel 'type' column to specify the order of factor levels
mutate(type = fct_relevel(type, c("Self", "Cross"))) |>
# Fit linear regression model with 'height' as the response variable and 'type' as the predictor
lm(height ~ type, data = _) |>
# Tidy the model summary
broom::tidy()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 17.575000 | 0.7592028 | 23.149282 | 0.0000000 |
| typeCross | 2.616667 | 1.0736749 | 2.437113 | 0.0214145 |
After releveling, the self treatment is now taken as the intercept, and we get the estimate for it’s mean and standard error
18.5.2 Emmeans
We could also use the package emmeans and its function emmeans() to do a similar thing
type emmean SE df lower.CL upper.CL
Cross 20.2 0.759 28 18.6 21.7
Self 17.6 0.759 28 16.0 19.1
Confidence level used: 0.95 The advantage of emmeans is that it provides the mean, standard error and 95% confidence interval estimates of all levels from the model at once (e.g. it relevels the model multiple times behind the scenes).
emmeans also gives us a handy summary to include in data visuals that combine raw data and statistical inferences. These are standard ggplot() outputs so can be customised as much as you want.
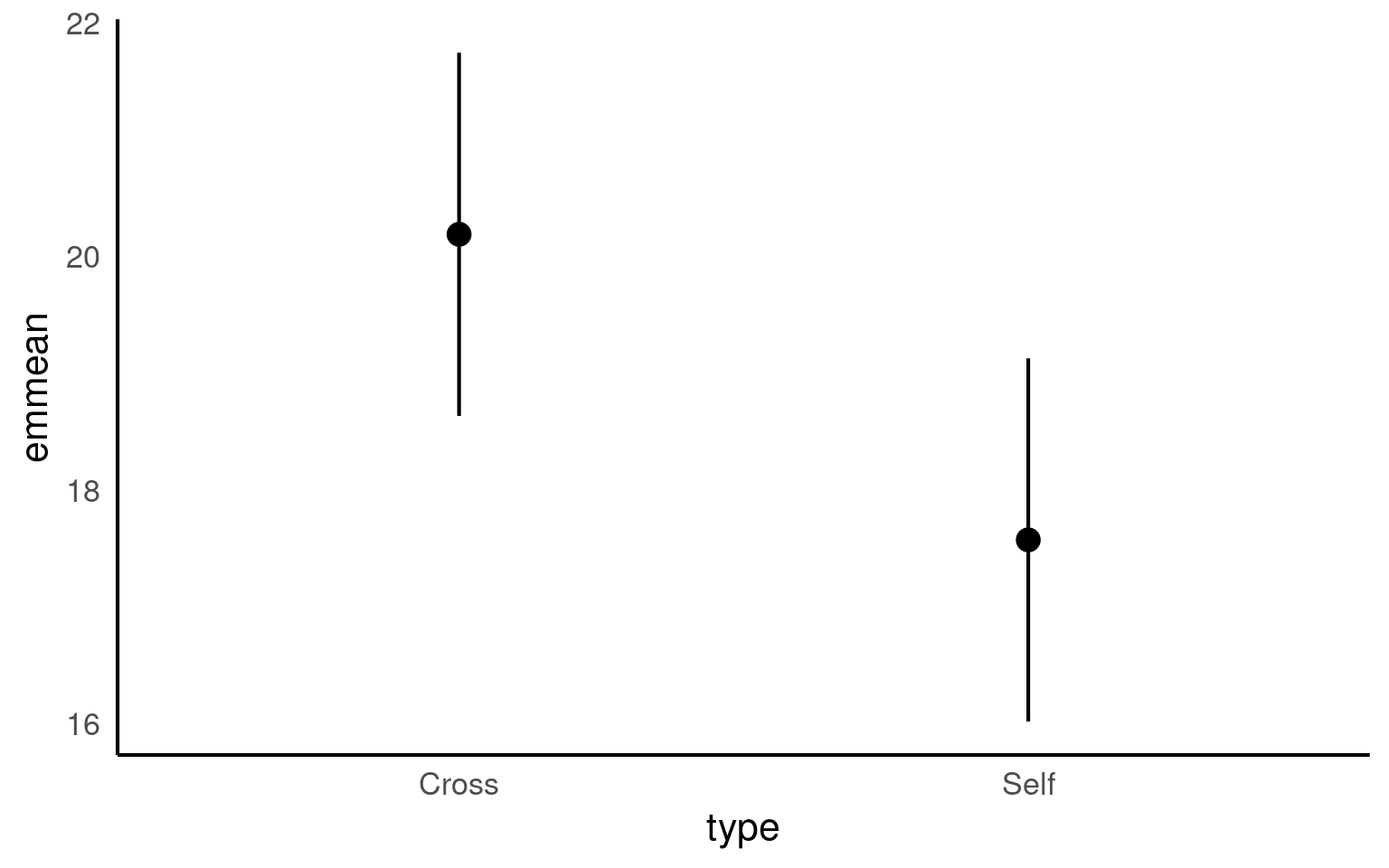
# Convert the 'means' object to a tibble
means |>
as_tibble() |>
# Create a plot using ggplot
ggplot(aes(x = type, y = emmean)) +
# Add point estimates with error bars
geom_pointrange(aes(ymin = lower.CL, ymax = upper.CL))+
# add raw data
geom_jitter(data = darwin,
aes(x = type,
y = height),
width = .1,
alpha = .4)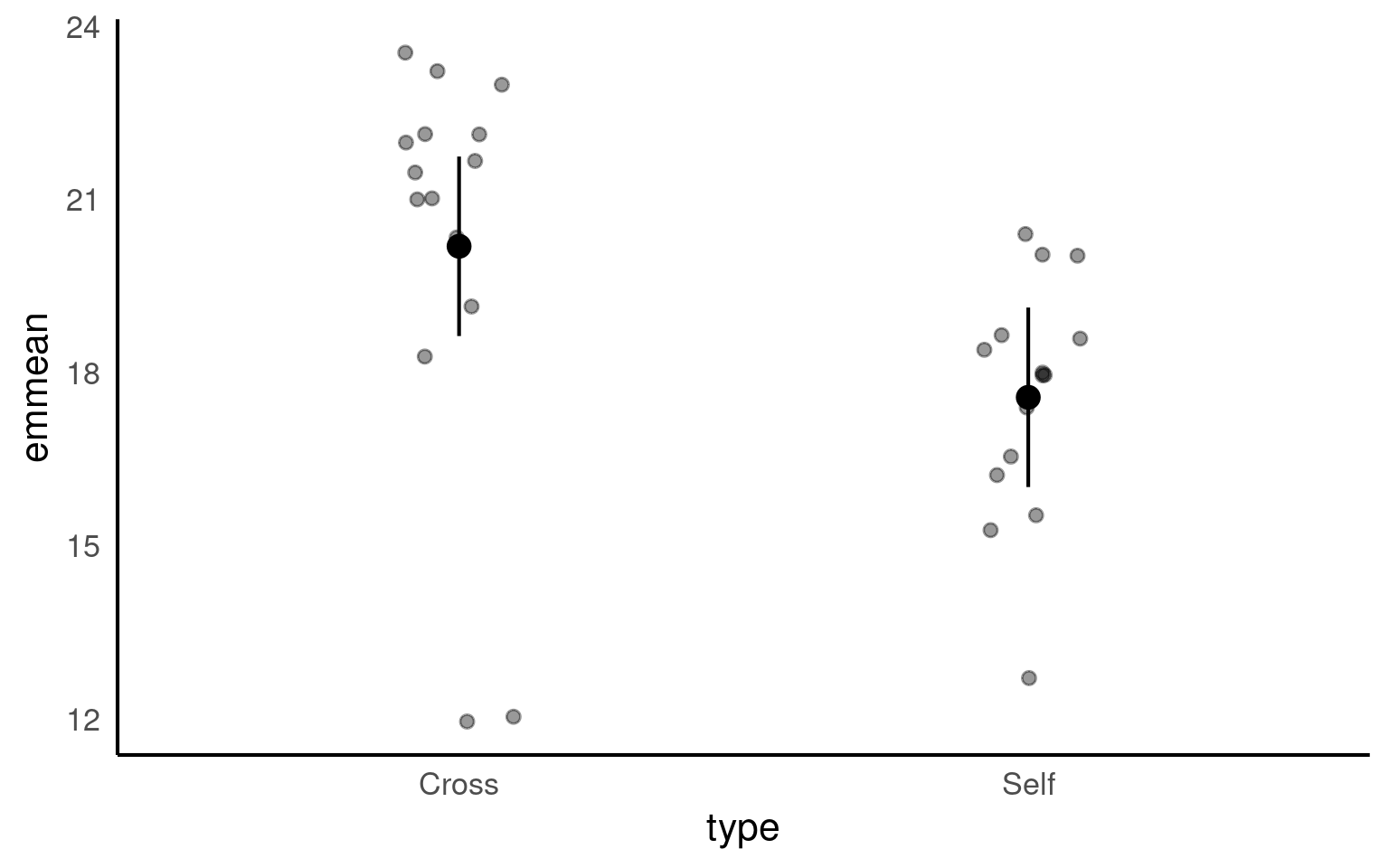
Notice that no matter how we calculate the estimated SE (and therefore the 95% CI) of both treatments is the same. This is because as mentioned earlier the variance is a pooled estimate, e.g. variance is not being calculate separately for each group. The only difference you should see in SE across treatments will be if there is a difference in sample size between groups.
Notice how the Confidence Intervals of the estimated means strongly overlap, there is a difference between the two SEMs and the SED we have calculated. So overlapping error bars cannot be used to infer significance.
Because of this pooled variance, there is an assumption that variance is equal across the groups, this and other assumptions of the linear model should be checked. We cannot trust our results if the assumptions of the model are not adequately met.
18.6 Summary
So remember a linear model sets one factor level as the ‘intercept’ estimates its mean, then draws a line from the first treatment to the second treatment, the slope of the line is the difference in means between the two treatments.
The difference in means is always accompanied by a standard error of the difference (SED), and this can be used to calculate a 95% confidence interval. If this confidence interval does not contain the intercept value, we can reject the null hypothesis that there is ‘no effect’.
Linear models make a variety of assumptions, including that the noise (residual differences) are approximately normally distributed, with roughly equal (homogenous) variance.
18.7 Write-up
Can you write an Analysis section? Add calculated 95% confidence intervals on top of the summary we produced earlier
The maize plants that have been cross pollinated had an average height of 20.19 inches [18.63 - 21.74] and were taller on average than the self-pollinated plants, with a mean difference in height of 2.62 [0.42, 4.82] inches (mean [95% CI]) (t(28) = -2.44, p = 0.02).
# Convert the 'means' object to a tibble
means |>
as_tibble() |>
# Create a plot using ggplot
ggplot(aes(x = type, y = emmean, fill = type)) +
# Add raw data
geom_jitter(data = darwin,
aes(x = type,
y = height),
width = 0.1,
pch = 21,
alpha = 0.4) +
# Add point estimates with 95% confidence error bars
geom_pointrange(aes(ymin = lower.CL,
ymax = upper.CL),
pch = 21) +
labs(x = "Breeding Type",
y = "Height (inches) ± 95% CI")+
theme_classic()+
theme(legend.position = "none")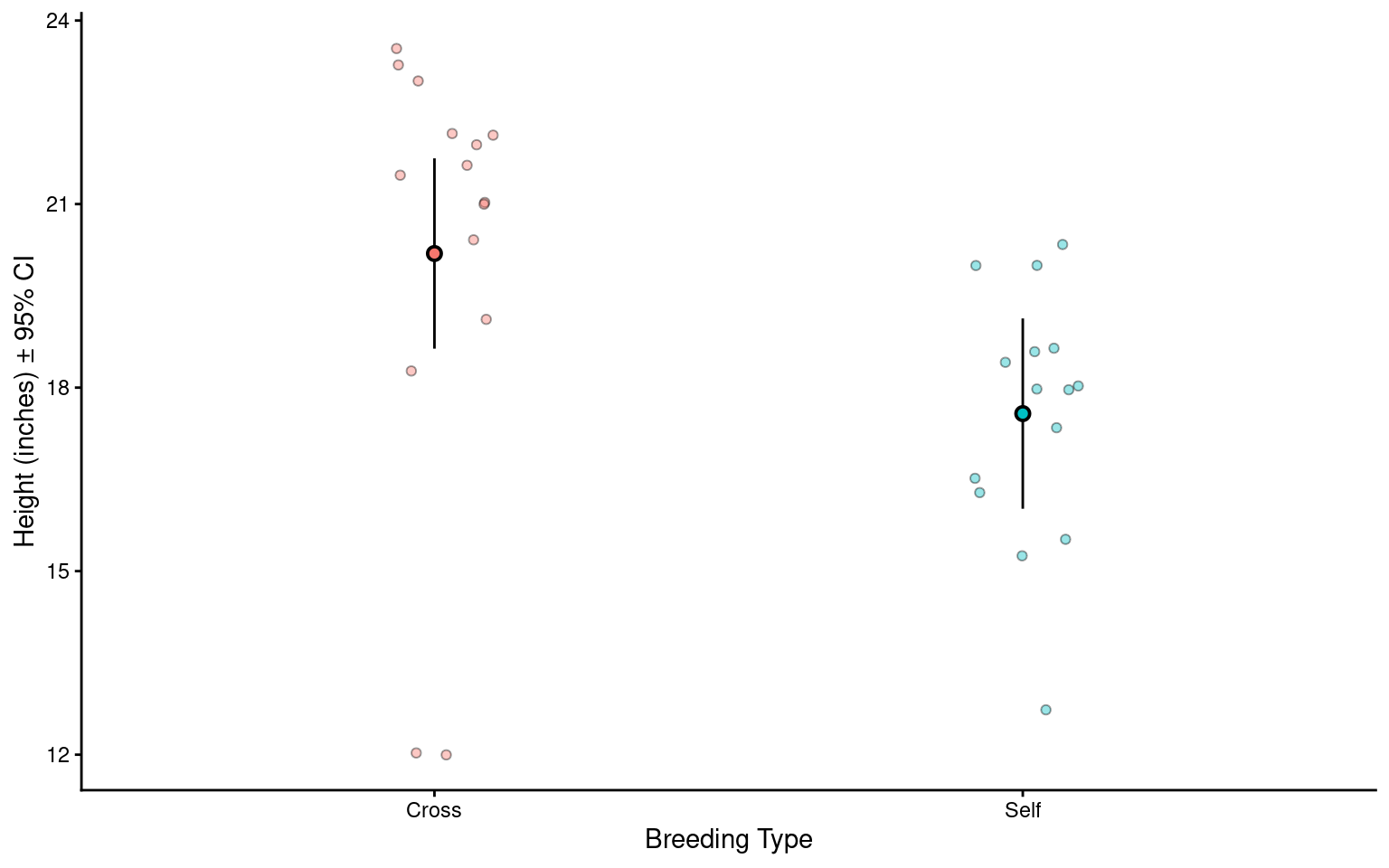
This will be different to your previous manual calculations on two counts. One, we are using a t-distribution for our confidence intervals. Two this example is a two-sample t-test, our previous example was closer to a paired t-test we will see how to implement a linear model with a paired design in subsequent chapters.