16 Regression
16.1 Introduction to Regression
So far we have used linear models for analyses between two 'categorical' explanatory variables e.g. t-tests. But what about when we have a 'continuous' explanatory variable? For that we need to use a regression analysis, luckily this is just another 'special case' of the linear model, so we can use the same lm() function we have already been using, and we can interpret the outputs in the same way.
16.2 Linear regression
Much like the t-test we have generating from our linear model, the regression analysis is interpreting the strength of the 'signal' (the change in mean values according to the explanatory variable), vs the amount of 'noise' (variance around the mean).
We would normally visualise a regression analysis with a scatter plot, with the explanatory (predictor, independent) variable on the x-axis and the response (dependent) variable on the y-axis. Individual data points are plotted, and we attempt to draw a straight-line relationship throught the cloud of data points. This line is the 'mean', and the variability around the mean is captured by calculated standard errors and confidence intervals from the variance.
The equation for the linear regression model is:
\[ y = a + bx \] You may also note this is basically identical to the equation for a straight fit line \(y = mx +c\).
Here:
y is the predicted value of the response variable
a is the regression intercept (the value of y when x = 0)
b is the slope of the regression line
x is the value of the explanatory variable
This formula explains the mean, you would need to include the unexplained residual error as a term to include our measure of uncertainty
\[ y = a + bx + e \]
The regression uses two values to fit a straight line. First we need a starting point, known as the regression intercept. For categorical predictors this is the mean value of y for one of our categories, for a regression this is the mean value of y when x = 0. We then need a gradient (how the value of y changes when the value of x changes). This allows us to draw a regression line.
A linear model analysis estimates the values of the intercept and gradient in order to predict values of y for given values of x.
16.3 Data
Here we are going to use example data from the Australian forestry industry, recording the density and hardness of 36 samples of wood from different tree species. Wood density is a fundamental property that is relatively easy to measure, timber hardness, is quantified as the 'the amount of force required to embed a 0.444" steel ball into the wood to half of its diameter'.
With regression, we can test the biological hypothesis that wood density can be used to predict timber hardness, and use this regression to predict timber hardness for new samples of known density.
Timber hardness is quantified using the 'Janka scale', and the data we are going to use today comes originally from an R package SemiPar
Check the data is imported correctly and make sure it is 'tidy' with no obvious errors or missing data
16.4 Activity 1: Exploratory Analysis
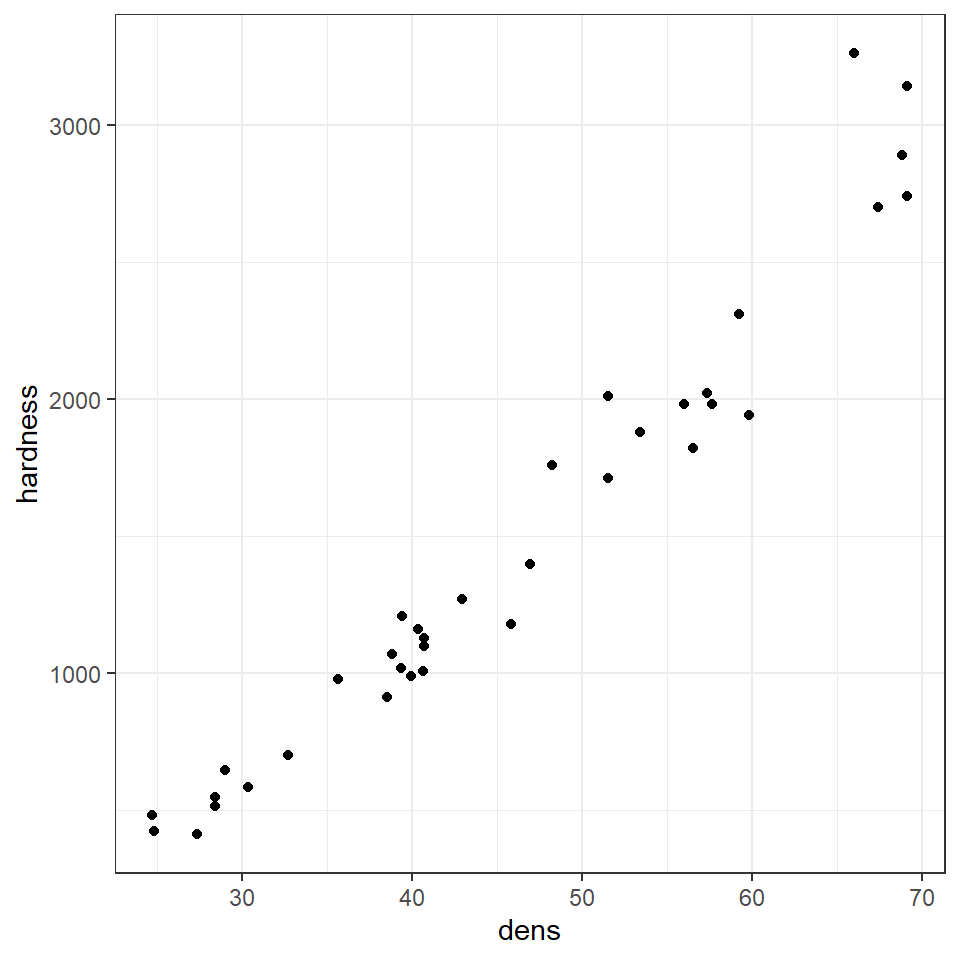
Wood density and timber hardness appear to be positively related, and the relationship appears to be fairly linear. We can look at a simple strength of this association between dens and hardness using correlation
16.5 Activity 2: Correlation - Generate Pearson's R
Can you work out the code needed to generate Pearson's R? - Try using a google search, then check your code and answer against the solution.
Hint try the rstatix package?
Correlation coefficients range from -1 to 1 for perfectly negative to perfectly positive linear relationships. The relationship here appears to be strongly positive. Correlation looks at the association between two variables, but we want to go further - we are arguing that wood density causes higher values of timber hardness. In order to test that hypothesis we need to go further than correlation and use regression.
16.6 Regression in R
We can fit the regression model in exactly the same way as we fit the linear model for Darwin's maize data. The only difference is that here our predictor variable is continuous rather than categorical.
Be careful when ordering variables here:
-
the left of the 'tilde' is the response variable,
-
on the right is the predictor.
Get them the wrong way round and it will reverse your hypothesis.
janka_ls1 <- lm(hardness ~ dens, data = janka) This linear model will estimate a 'line of best fit' using the method of 'least squares' to minimise the error sums of squares (the average distance between the data points and the regression line).
We can add a regression line to our ggplots very easily with the function geom_smooth().
# specify linear model method for line fitting
janka %>%
ggplot(aes(x=dens, y=hardness))+
geom_point()+
geom_smooth(method="lm")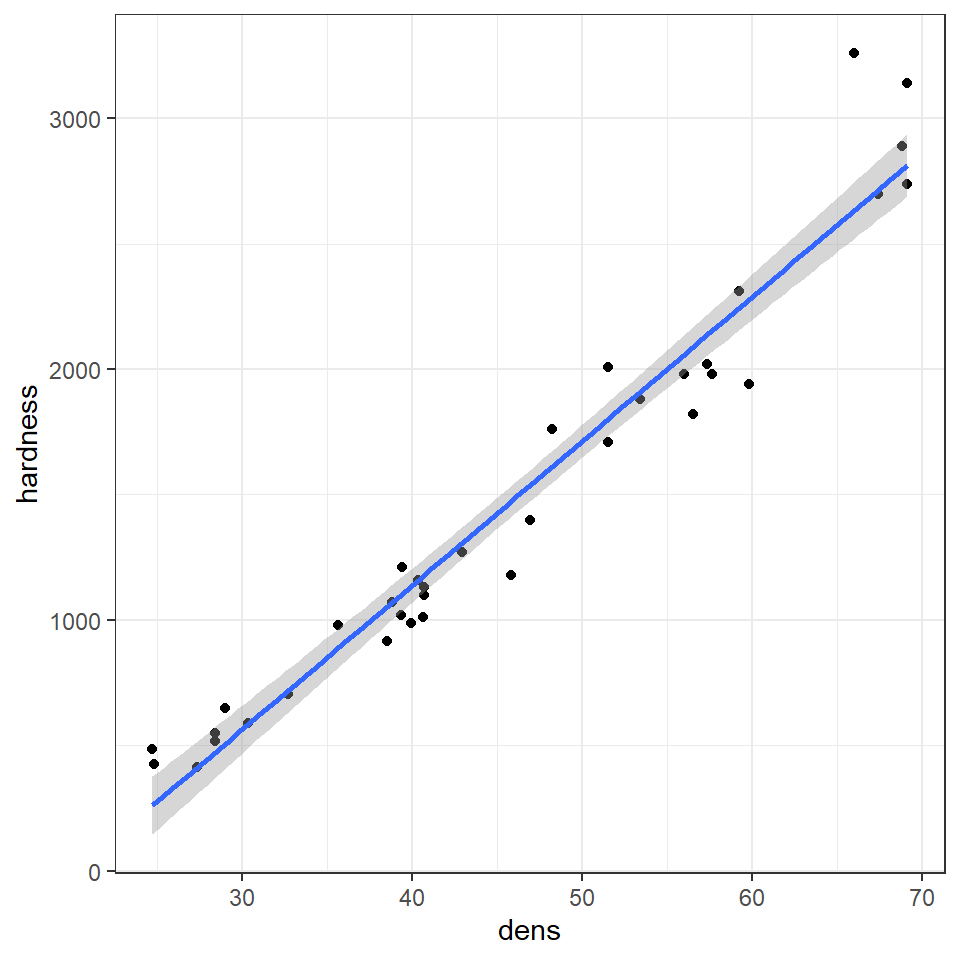
Q. The blue line represents the regression line, and the shaded interval is the 95% confidence interval band. What do you notice about the width of the interval band as you move along the regression line?
The 95% confidence interval band is narrowest in the middle and widest at either end of the regression line. But why?
When performing a linear regression, there are two types of uncertainty in the prediction.
First is the prediction of the overall mean of the estimate (ie the center of the fit). The second is the uncertainly in the estimate calculating the slope.
So when you combine both uncertainties of the prediction there is a spread between the high and low estimates. The further away from the center of the data you get (in either direction), the uncertainty of the slope becomes a large and more noticeable factor, thus the limits widen.
16.6.1 Summary
summary(janka_ls1)##
## Call:
## lm(formula = hardness ~ dens, data = janka)
##
## Residuals:
## Min 1Q Median 3Q Max
## -338.40 -96.98 -15.71 92.71 625.06
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1160.500 108.580 -10.69 2.07e-12 ***
## dens 57.507 2.279 25.24 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 183.1 on 34 degrees of freedom
## Multiple R-squared: 0.9493, Adjusted R-squared: 0.9478
## F-statistic: 637 on 1 and 34 DF, p-value: < 2.2e-16
janka_ls1 %>%
broom::tidy()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -1160.49970 | 108.579605 | -10.68801 | 0 |
| dens | 57.50667 | 2.278534 | 25.23845 | 0 |
This output should look very familiar to you, because it's the same output produced for the analysis of the maize data. Including a column for the coefficient estimates, standard error, t-statistic and P-value. The first row is the intercept, and the second row is the difference in the mean from the intercept caused by our explanantory variable.
In many ways the intercept makes more intuitive sense in a regression model than a difference model. Here the intercept describes the value of y (timber hardness) when x (wood density) = 0. The standard error is standard error of this calculated mean value. The only wrinkle here is that that value of y is an impossible value - timber hardness obviously cannot be a negative value (anti-hardness???). This does not affect the fit of our line, it just means a regression line (being an infinite straight line) can move into impossible value ranges.
One way in which the intercept can be made more valuable is to use a technique known as 'centering'. By subtracting the average (mean) value of x from every data point, the intercept (when x is 0) can effectively be right-shifted into the centre of the data.
16.7 Activity 3: Mean centered regression
Note how the estimate for row 2 - the effect of density on timber hardness has not changed, but the intercept now represents the estimated mean timber hardness for the mean wood density e.g. at a density of \(\rho\) = 45.73 the average timber hardness on the janka scale is 1469.
16.7.1 the second row
The second row is labelled 'dens'. Density is our explanatory variable, and the slope is estimated against it. So if 57.5 is the value of the regression slope (with its standard error) - then the timber hardness is predicted to increase by 57.5 on the janka scale for every unit change of density.
According to our model summary, this estimated change in the mean is statistically significant - so for this effect size and sample size it is unlikely that we would observe this relationship if the null hypothesis (that we cannot predict timber hardness from wood density) were true.
16.7.2 Confidence intervals
Just like with the maize data, we can produce upper and lower bounds of confidence intervals:
confint(janka_ls1)## 2.5 % 97.5 %
## (Intercept) -1381.16001 -939.83940
## dens 52.87614 62.13721
broom::tidy(janka_ls1, conf.int=T, conf.level=0.95)| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | -1160.49970 | 108.579605 | -10.68801 | 0 | -1381.16001 | -939.83940 |
| dens | 57.50667 | 2.278534 | 25.23845 | 0 | 52.87614 | 62.13721 |
16.7.3 Effect size
With a regression model, we can also produce a standardised effect size. The estimate and 95% confidence intervals are the amount of change being observed, but just like with the maize data we can produce a standardised measure of how strong the relationship is. This value is represented by \(R^2\) : the proportion of the variation in the data explained by the linear regression analysis.
The value of \(R^2\) can be found in the model summaries as follows
summary(janka_ls1)##
## Call:
## lm(formula = hardness ~ dens, data = janka)
##
## Residuals:
## Min 1Q Median 3Q Max
## -338.40 -96.98 -15.71 92.71 625.06
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1160.500 108.580 -10.69 2.07e-12 ***
## dens 57.507 2.279 25.24 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 183.1 on 34 degrees of freedom
## Multiple R-squared: 0.9493, Adjusted R-squared: 0.9478
## F-statistic: 637 on 1 and 34 DF, p-value: < 2.2e-16
janka_ls1 %>%
broom::glance()| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual | nobs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.9493278 | 0.9478374 | 183.0595 | 636.9794 | 0 | 1 | -237.6061 | 481.2123 | 485.9628 | 1139366 | 34 | 36 |
| Effect size | r^2 |
|---|---|
| small | 0.1 |
| medium | 0.3 |
| large | 0.5 |
16.8 Assumptions
Regression models make ALL the same assumptions as all linear models - that the unexplained variation around the regression line (the residuals) is approximately normally distributed, and has constant variance. And we can check this in the same way.
Remember, the residuals are the difference between the observed values and the fitted values predicted by the model. Or in other words it is the vertical distance between a data point and the fitted value on the regression line. We can take a look at this with another function in the broom package augment(). This generates the predicted value for each data point according to the regression, and calculates the residuals for each data point.
## 1 2 3 4 5 6 7 8
## 259.9152 265.6658 409.4325 472.6899 472.6899 507.1939 581.9525 719.9686
## 9 10 11 12 13 14 15 16
## 886.7379 1053.5073 1070.7593 1099.5126 1105.2633 1134.0166 1157.0193 1174.2713
## 17 18 19 20 21 22 23 24
## 1180.0220 1180.0220 1306.5366 1473.3060 1536.5633 1611.3220 1801.0940 1801.0940
## 25 26 27 28 29 30 31 32
## 1910.3567 2059.8741 2088.6274 2134.6328 2151.8848 2243.8954 2278.3994 2634.9408
## 33 34 35 36
## 2715.4502 2795.9595 2813.2115 2813.2115
## 1 2 3 4 5 6
## 224.0848370 161.3341695 3.5674826 44.3101404 76.3101404 140.8061355
## 7 8 9 10 11 12
## 5.0474583 -15.9685611 92.2620821 -139.5072748 -0.7592772 -79.5126146
## 13 14 15 16 17 18
## 104.7367180 -145.0166194 2.9807107 -164.2712918 -80.0219592 -50.0219592
## 19 20 21 22 23 24
## -36.5366437 -293.3060005 -136.5633428 148.6779800 -91.0940467 208.9059533
## 25 26 27 28 29 30
## -30.3567287 -79.8740831 -268.6274205 -114.6327603 -171.8847628 66.1045576
## 31 32 33 34 35 36
## -338.3994472 625.0591692 -15.4501754 94.0404799 -73.2115225 326.7884775| hardness | dens | .fitted | .resid | .hat | .sigma | .cooksd | .std.resid |
|---|---|---|---|---|---|---|---|
| 484 | 24.7 | 259.9152 | 224.084837 | 0.0963176 | 181.2248 | 0.0883658 | 1.2876929 |
| 427 | 24.8 | 265.6658 | 161.334170 | 0.0956674 | 183.4505 | 0.0454303 | 0.9267658 |
| 413 | 27.3 | 409.4325 | 3.567483 | 0.0804200 | 185.8113 | 0.0000181 | 0.0203224 |
| 517 | 28.4 | 472.6899 | 44.310140 | 0.0743247 | 185.6394 | 0.0025410 | 0.2515831 |
| 549 | 28.4 | 472.6899 | 76.310140 | 0.0743247 | 185.2987 | 0.0075364 | 0.4332720 |
| 648 | 29.0 | 507.1939 | 140.806136 | 0.0711580 | 184.0637 | 0.0243988 | 0.7981020 |
If we plot this, with a black fitted regression line and red dashed lines representing the residuals:
augmented_ls1 <- janka_ls1 %>%
broom::augment()
augmented_ls1 %>%
ggplot(aes(x=dens,
y=.fitted))+
geom_line()+
geom_point(aes(x=dens,
y=hardness))+
geom_segment(aes(x=dens,
xend=dens,
y=.fitted,
yend=hardness),
linetype="dashed", colour="red")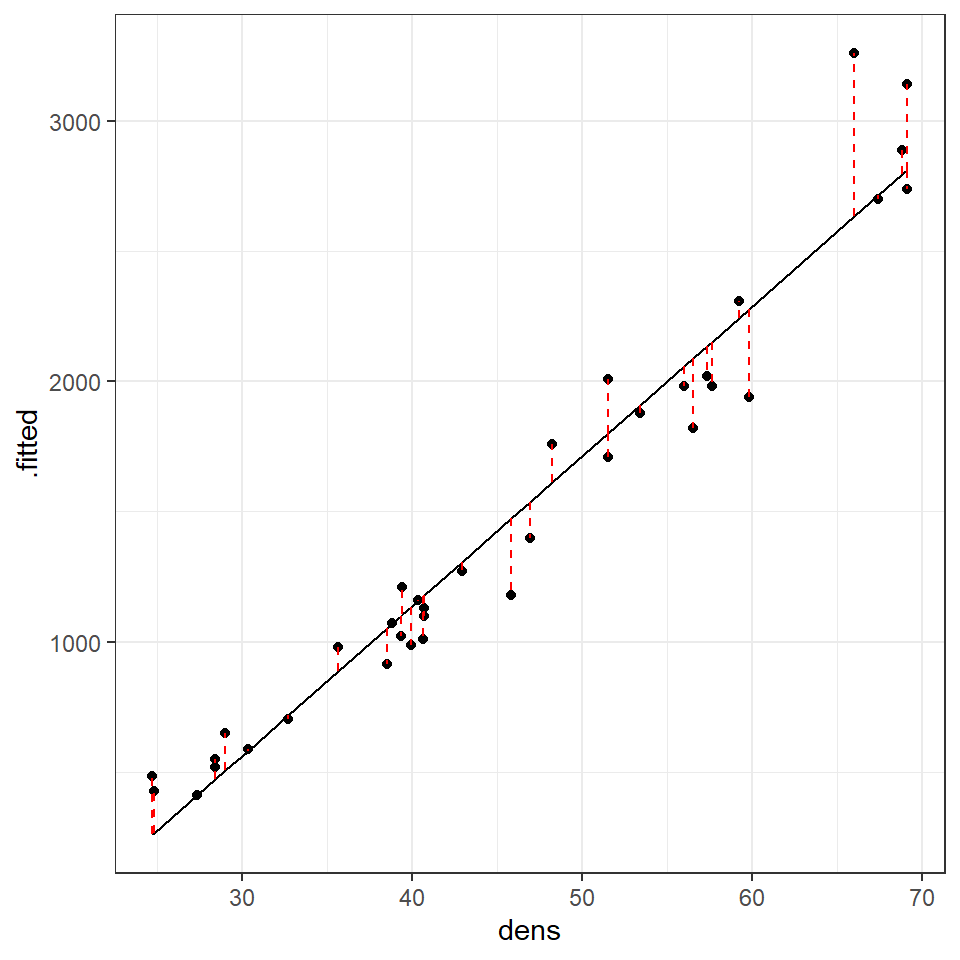
We can use this augmented data to really help us understand what residual variance looks like, and how it can be used to diagnose our models. A perfect model would mean that all of our residual values = 0, but this is incredibly unlikely to ever occur. Instead we would like to see
that there is a 'normal distribution' to the residuals e.g. more residuals close to the mean, and fewer further away in a rough z-distribution.
We also want to see homogeneity of the residuals e.g. it would be a bad model if the average error was greater at one end of the model than the other. This might mean we have more uncertainty in the slope of the line for large values over small values or vice versa.
# A line connecting all the data points in order
p1 <- augmented_ls1 %>%
ggplot(aes(x=dens, y=hardness))+
geom_line()+
ggtitle("Full Data")
# Plotting the fitted values against the independent e.g. our regression line
p2 <- augmented_ls1 %>%
ggplot(aes(x=dens, y=.fitted))+
geom_line()+
ggtitle("Linear trend")
# Plotting the residuals against the fitted values e.g. remaining variance
p3 <- augmented_ls1 %>%
ggplot(aes(x=.fitted, y=.resid))+
geom_hline(yintercept=0, colour="white", size=5)+
geom_line()+
ggtitle("Remaining \npattern")
library(patchwork)
p1+p2+p3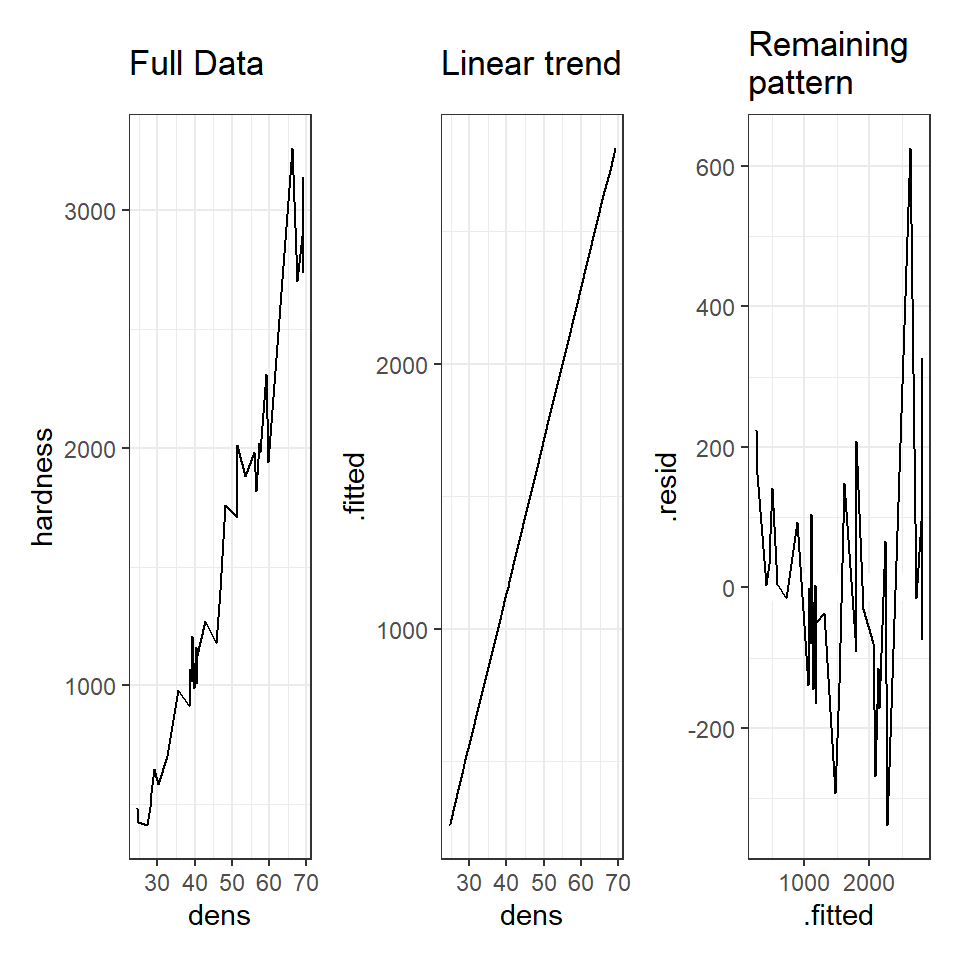
The above is an example of functional, but repetitive code - could you make a function that reduces the amount of code needed?
HINT - to make sure your arguments for a ggplot are passed properly use this structure x=.data[[x]] , y = .data[[y]]This is an example of the function we want to make:
model_plot(data=augmented_ls1,
x="dens",
y="hardness",
title="Full data")16.8.1 Normal distribution
We can use the same model diagnostic plots as we used for the maize data. Here you can see it is mostly pretty good, with just one or two data points outside of the confidence intervals
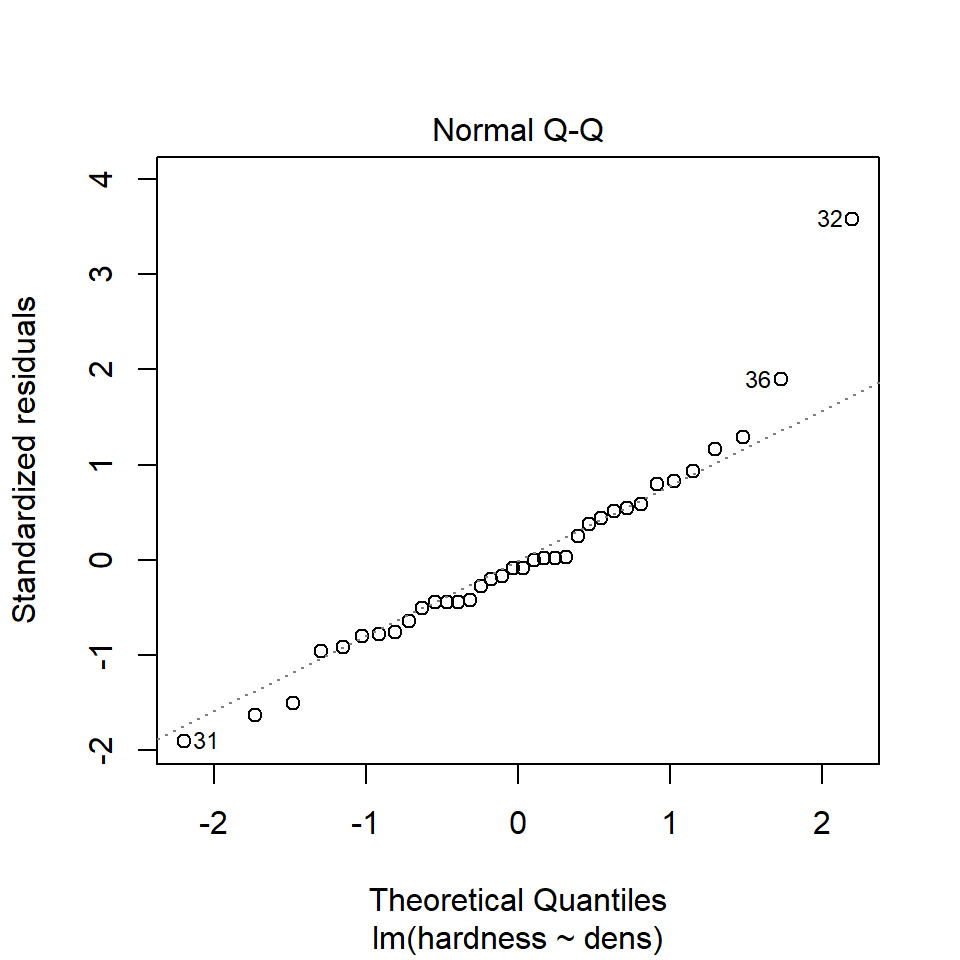

16.8.2 Equal variance
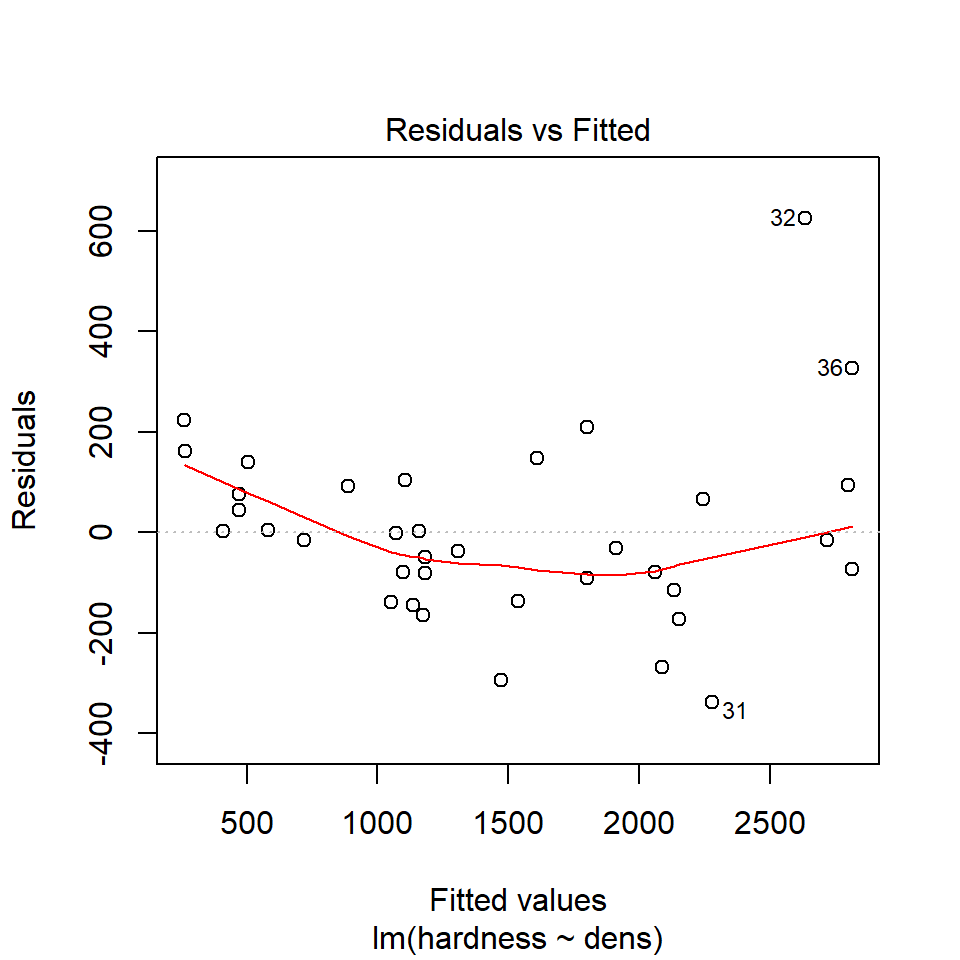
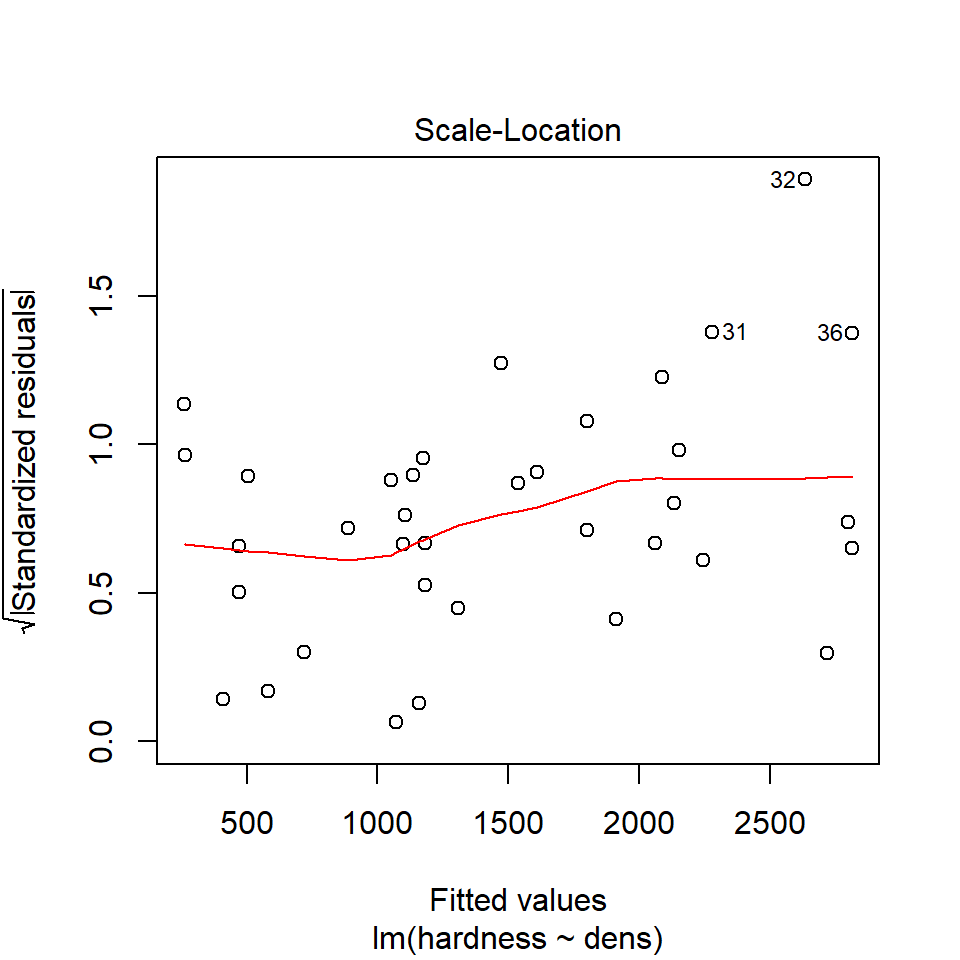
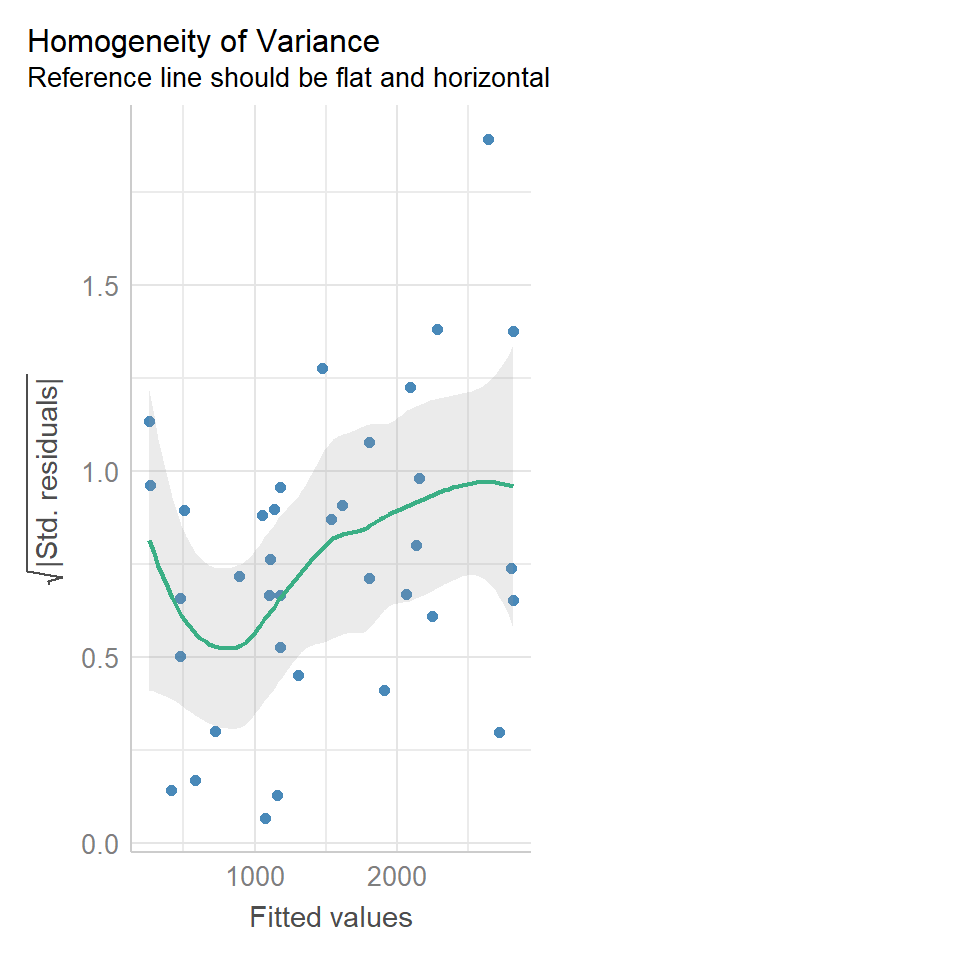
We can use the same model diagnostic plots as we used for the maize data.
You should see that this is similar to the p3 plot we constructed manually. With the plot we constructed earlier we had the 'raw' residuals as a function of the fitted values. The plot we have produced now is the 'standardized residuals' - this is the raw residual divided by the standard deviation.
Both plots suggests that the residuals do not have constant variance, broadly speaking the amount of variance y increases as x increases. This means we have less confidence in our predictions at high values of density. Later we will see what we can do to improve the fit of this model

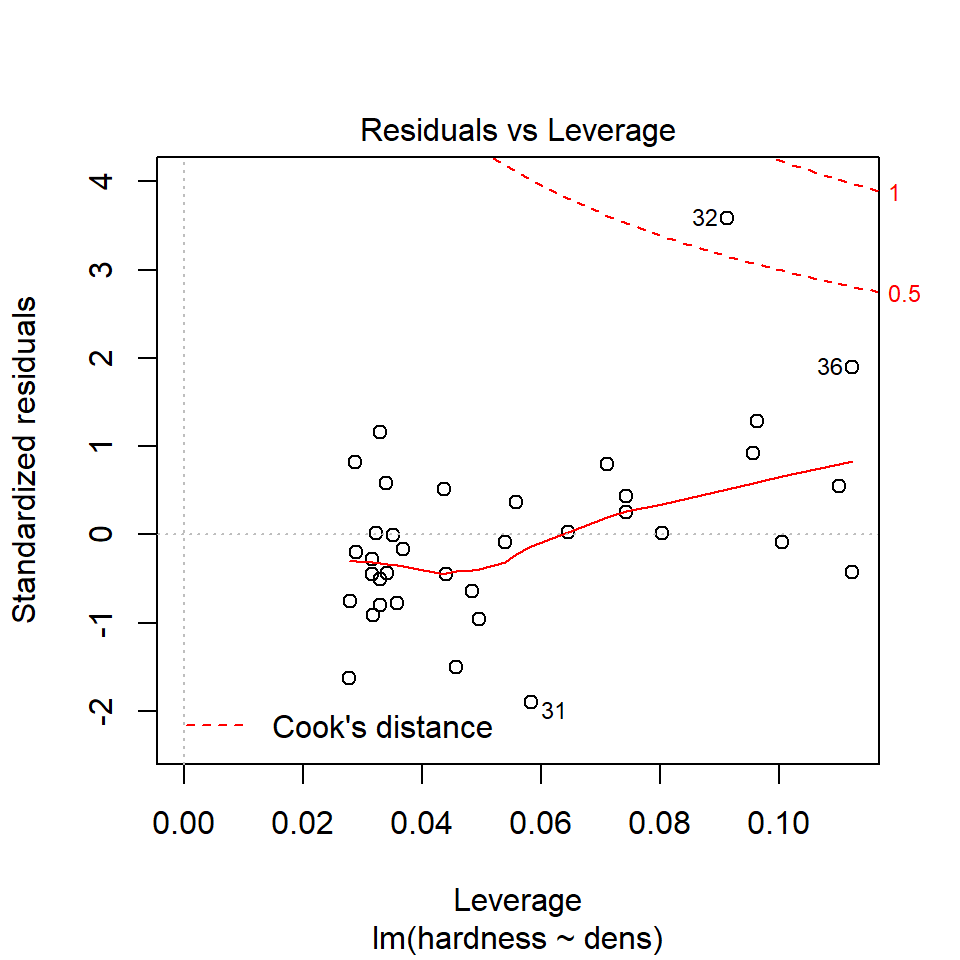
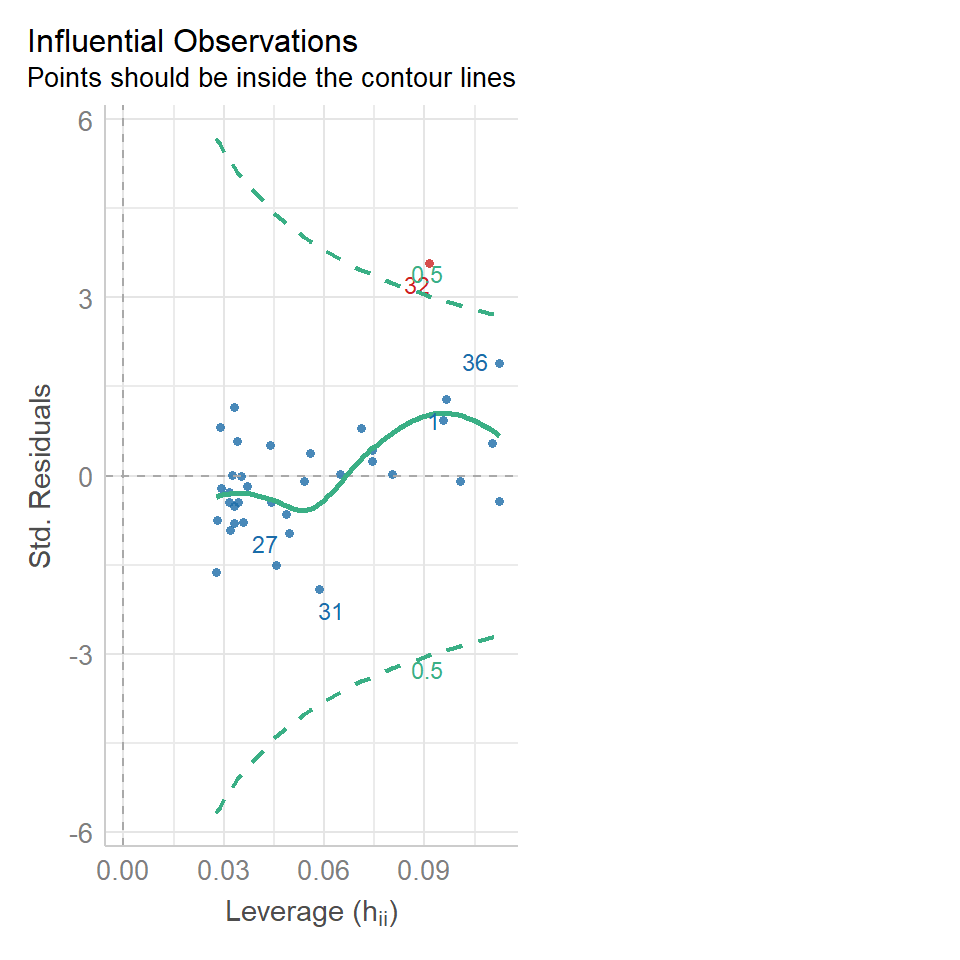
16.9 Prediction
Using the coefficients of the intercept and the slope we can make predictions on new data. The estimates of the intercept and the slope are:
coef(janka_ls1)## (Intercept) dens
## -1160.49970 57.50667Now imagine we have a new wood samples with a density of 65, how can we use the equation for a linear regression to predict what the timber hardness for this wood sample should be?
\[ y = a + bx \]
Rather than work out the values manually, we can also use the coefficients of the model directly
## (Intercept)
## 2577.434But most of the time we are unlikely to want to work out predicted values by hand, instead we can use functions like predict() and broom::augment()
16.9.1 Adding confidence intervals
16.9.1.1 Standard error
| dens | .fitted | .se.fit |
|---|---|---|
| 22 | 104.6471 | 62.09026 |
| 35 | 852.2339 | 39.10197 |
| 65 | 2577.4342 | 53.46068 |
16.9.1.2 95% Confidence Intervals
| dens | .fitted | .lower | .upper |
|---|---|---|---|
| 22 | 104.6471 | -21.53544 | 230.8297 |
| 35 | 852.2339 | 772.76915 | 931.6987 |
| 65 | 2577.4342 | 2468.78899 | 2686.0793 |
I really like the emmeans package - it is very good for producing quick predictions for categorical data - it can also do this for continuous variables. By default it will produce a single mean-centered prediction. But a list can be provided - it will produce confidence intervals as standard.
16.10 Activity 4: Prediction
Hint - first make a new R object that contains your predictions, then work out how to add two dataframes to one plot.
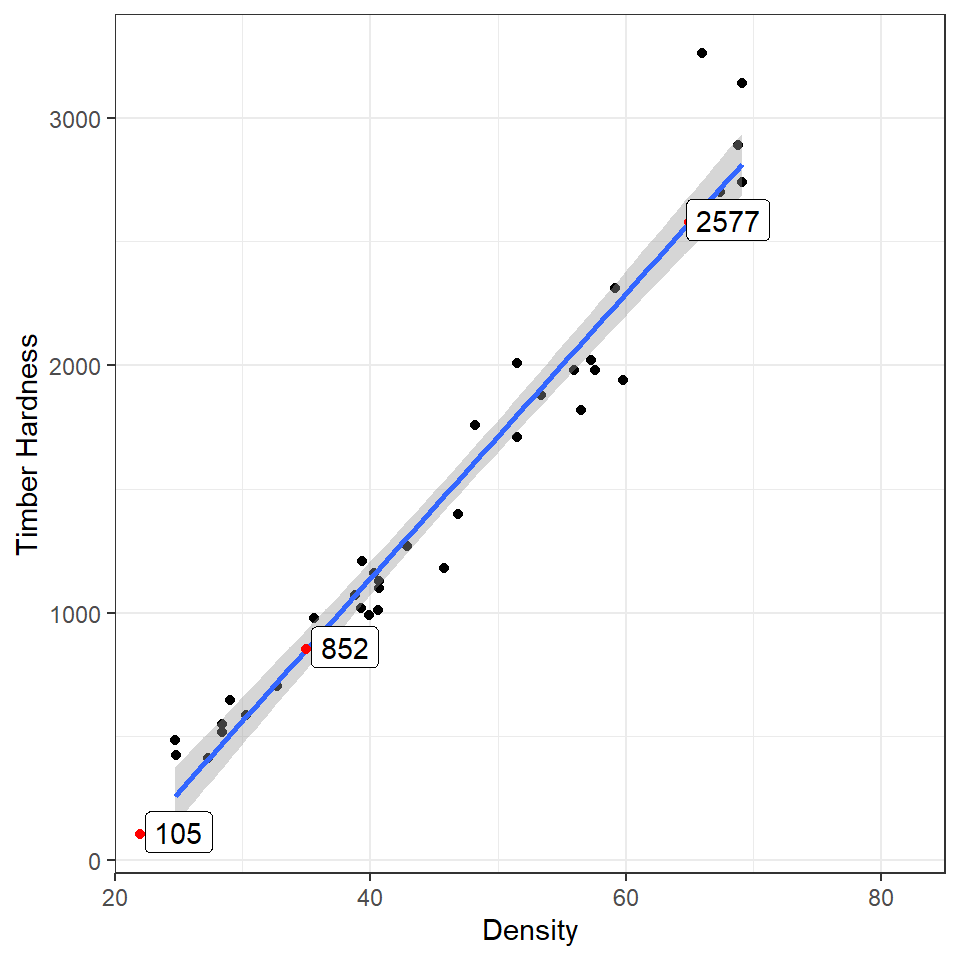
16.11 Summary
Linear model analyses can extend beyond testing differences of means in categorical groupings to test relationships with continuous variables. This is known as linear regression, where the relationship between the explanatory variable and response variable are modelled with the equation for a straight line. The intercept is the value of y when x = 0, often this isn't that useful, and we can use 'mean-centered' values if we wish to make the intercept more intuitive. As with all linear models, regression assumes that the unexplained variability around the regression line, is normally distributed and has constant variance.
Once the regression has been fitted it is possible to predict values of y from values of x, the uncertainty around these predictions can be captured with confidence intervals.