17 ANOVA
17.1 Analysis of Variance (ANOVA)
So far we have used linear models for analyses between two 'categorical' explanatory variables e.g. t-tests, and for regression with two 'continuous' variables. However, as designs become more complicated, the number of comparisons can quickly become overwhelming, working with estimates and intervals alone can become harder.
As designs become more elaborate the number of pairwise t-tests rapidly increases, and therefore our risk of false positives (Type I errors). It is therefore useful to have a complementary approach that first asks if there is any support for a difference between the different means before diving into multiple comparisons. This approach is called analysis of variance (ANOVA), and although it tends to be associated with categorical data, we will see in the following chapters that the ANOVA is just another type of linear model, so this approach can also be extended to included continuous variables.
17.2 Maize data
Our simple linear model for the maize data was:
lsmodel1 <- lm(height ~ type, data = darwin)This structure of fitting a linear model, with one explanatory variable is also known as a one-way ANOVA. The general strategy of the ANOVA is to quantify the overall variability in the data set and then to divide it into the variability between and within the groups. We can also refer to this as the 'signal-to-noise' ratio, or the variability explained by the slope of the linear model, vs unexplained variance.
The more of the variation explained by our fitted linear model, the more confident we can be that we have detected a real effect in our estimates of mean differences. This method of fitting a model is called ordinary least squares.
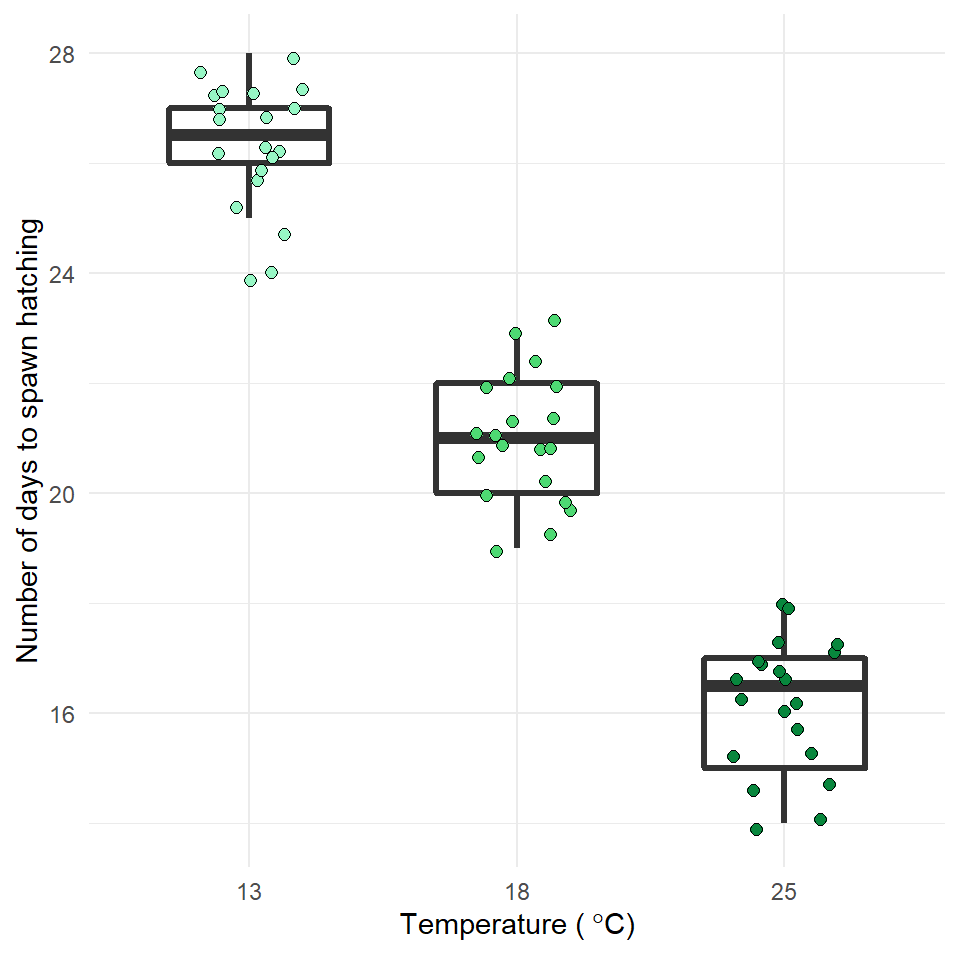
The least squares model first quantifies the total amount of variation (total sum of squares, SST) by measuring the difference from the individual data points to a reference point (usually the 'grand' mean, see below).
Next the model quantifies a fitted slope, it aims to produce a slope that produces the least amount of squared residuals to the data points (sum of squares of the regression/ANOVA, SSR/A).
This then leaves the residual unexplained variation (sum of squares of the error, SSE).
In this way the model is splitting the overall variability (SST) into signal (SSR) and noise (SSE):
\[ SST = SSR + SSE \]
Remember:
SST = the sum of squared differences between the data points and the grand mean
SSR = the sum of the squared differences between the grand mean and the predicted position on the linear model
SSE = the sum of the squared differences between the predicted position and the observed position
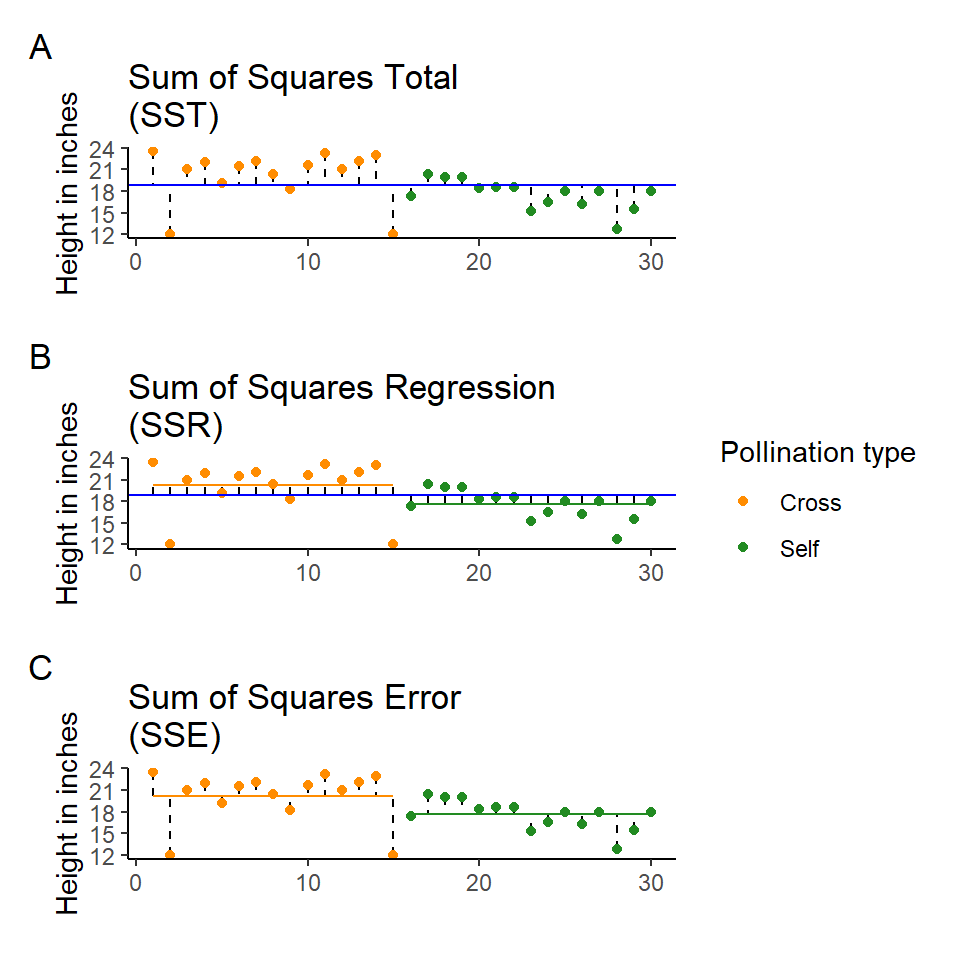
Least squares quantifies A) total least squares, B) treatment least squares, C) error sum of squares (SST, SSR, SSE). The vertical lines measure the distances, which are then squared and summed. SST is calculated by measuring to the intercept, SSR is calculated by measuring the distance of the estimates to the intercept, SSE is calculated by measuring the distance to the estimates
17.2.1 The ANOVA table
If we want to get the ANOVA table for a linear model we can use the anova() function:
anova(lsmodel1)| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| type | 1 | 51.35208 | 51.352083 | 5.939518 | 0.0214145 |
| Residuals | 28 | 242.08333 | 8.645833 | NA | NA |
Compare this to the output you get when you use the summary() function. You should see that the F-value P-value and df are all exactly the same. The ANOVA table actually has far less information in it, as it contains no information about the biology (estimates in difference, or uncertainty such as standard errors etc.). It is amazing how many times you will see these tables reported, even though they contain the least interesting part of the analysis.
BUT they can help us simplify effects where there are more than two levels, but we need to learn how to use them appropriately.
The ANOVA table has six columns and two rows of information.
The first column contains the information source, here the signal/regression (first row) and error/noise (second row).
The second column gives the degrees of freedom, in the first row this is the number of predictors(treatments) (k - 1, including intercept), and in the second row the residual degrees of freedom (N - k).
The third column is the sum of squares in the first row this is the SSR, and the second row SSE (remember that SST = SSR + SSE).
The fourth column is the mean sum of squares MSR = SSR/(k-1) & MSE = SSE/(N-k). These are the average amounts of variability per treatment level.
It's worth stopping briefly at this point and remembering that we have effectively pooled the SSE from both treatments to generate the MSE. Linear models always use this pooled variance approach, it can give them greater power for detecting effects with smaller sample sizes, but is the reason why we need homogeneity of variance as an assumption of our model.
The fifth column is our F statistic (the signal-to-noise ratio). It is calculated by dividing the treatment variance by the residual error variance
\[ F =\frac{SSR/(k-1)}{SSE/(N-k)} = \frac{MSR}{MSE} \] In our example F = 5.9, which means that the estimated signal is nearly six times larger than the estimated noise.
We can then use this F value with our sample size and treatment levels to calculate the probability of observing this ratio of signal to noise if the null hypothesis that there were no effect of treatment is true.
The probability value can be looked up in an ANOVA table, and is calculated from an F distribution. The F-test takes sample size into account, and the probability assigned takes into account the degrees of freedom of both the signal and noise.
We can see this if we use the R function pf() that this should recreate the exact P-value we see in our ANOVA table.
The first three arguments here are the F-value, degrees of freedom for the signal, and noise. The last argument is to set this as a two directional test.
pf(5.9395, 1, 28, lower.tail=FALSE)## [1] 0.02141466It is common to see P-values reported with no supporting information (naked P-values). But it is impossible to interpret these without knowing:
what test they came from
what the observed value of the test was
the degrees of freedom.
So the good (and conventional) way to report this result as an ANOVA would be:
The height of the cross-pollinated plants was significantly taller than the height of the self-pollinated plants (F1,28 = 5.9, P = 0.02).
BUT we know that this way of reporting, emphasises the statistical tests and not the underlying biology. The report doesn't tell us anything about the heights of the plants, the estimated difference between them, or any measure of the uncertainty around this.
The self pollinated maize plants measured an average of 17.6 [16-19.1] (mean[95% CI]) inches high, while the cross-pollinated plants had a mean height of 20.2 [18.6-21.7] inches - a difference of 2.6 [-0.4-4.8] inches (one-way ANOVA: F1,28 = 5.9, P = 0.02).
17.3 Two-way ANOVA
Two way ANOVA (as you might guess) includes two explanatory variables. Usually these are treatments of interest, but for this example we will stick with including the pair variable.
And we can look at this table using the anova() function again
anova(lsmodel2)| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| type | 1 | 51.35208 | 51.352083 | 4.6138501 | 0.0497029 |
| as.factor(pair) | 14 | 86.26354 | 6.161682 | 0.5536109 | 0.8597119 |
| Residuals | 14 | 155.81979 | 11.129985 | NA | NA |
Note how some of the degrees of freedom which were initially in the residuals, have now been 'used' by the new term in the more complex model. And that some of the SSE has now been used by SSR explained by the pair term.
As we should already have been able to predict from the last time that we looked at this model structure, the pairing doesn't really do anything ( here F< 1). If pairing did 'nothing' we would still expect an F ratio ~ 1. However, we can see that is actually quite a bit lower than this, and this implies a 'negative variance component' - it has actually increased the relative proportion of SSE compared to SSR here.
When mean squares of the regression are smaller than the residuals it implies a problem with the experimental design. It could be a result of undersampling (more pairs are needed), however it could also be that these pairs were not sampled at random.
17.4 Summary
ANOVA tables can be built for any linear model. The tables partition the variance into signal(s) and noise, which can be compared using an F-test. For complex analyses where many pairwise comparisons could be performed, an initial F-test can provide the initial evidence for whether there are any differences at all, reducing the risk of overtesting and the false positives that can be generated.
17.5 Activity
Write a short R based report (Rmd) using ANOVA to test an experimental hypothesis:
Set up a new R project for your analysis - get it talking to Github
Import, clean and analyse your data
Test an experimental hypothesis
Produce a data visual summary
Produce a short write-up
Now is the time to try and put your analysis skills into action. Below are instructions for importing data and setting up a new project to answer the question, does temperature affect frogspawn development? This is your chance to practice:
Q. How does frogspawn hatching time vary with temperature?
Imagine we ran a manipulative experiment.
A manipulative study is one in which the experimenter changes something about the experimental study system and studies the effect of this change.
We collected newly-layed frogspawn from a pond in the Italian Alps and we brought them back to the lab, where we divided them into 60 water containers. 20 of the containers’ water temperature was kept to 13°C, 20 containers were kept to 18°C and the remaining 20 containers were kept to 25°C. Having a high number of replicates increases our confidence that the expected difference between groups is due to the factor we are interested in. Here, temperature.
We monitored each water container and we recorded hatching times (days until hatching of eggs) in a spreadsheet (here called frogs_messy_data.csv).
Our response variable is Hatching_time.
Our explanatory variable is Temperature, with 3 levels: 13°C, 18°C and 25°C.
We want to compare the means of 3 independent groups (13°C, 18°C and 25°C temperature groups) and we have one continuous response variable (Hatching time in days) and one categorical explanatory variable (Temperature). One-way ANOVA is the appropriate analysis!
17.5.1 Hypothesis
Always make a hypothesis and prediction, before you delve into the data analysis.
A hypothesis is a tentative answer to a well-framed question, referring to a mechanistic explanation of the expected pattern. It can be verified via predictions, which can be tested by making additional observations and performing experiments.
This should be backed up by some level of knowledge about your study system.
In our case, knowing that frogspawn takes around 2-3 weeks to hatch under optimal temperatures (15-20°C), we can hypothesize that the lower the temperature, the longer it will take for frogspawn to hatch. Our hypothesis can therefore be: mean frogspawn hatching time will vary with temperature level. We can predict that given our temperature range, at the highest temperature (25°C) hatching time will be reduced.
After setting up your R project, import and tidy your dataset.
Hint: check your data is in a tidy format.
Remember to organise your analysis script - use the document outline feature to help you.