14 Model diagnostics
14.1 Learning Outcomes
By the end of this worksheet, you should be able to:
Explain and visually diagnose the key assumptions of linear regression.
Use R to check residual normality, variance, and linearity.
Identify when assumption violations are due to missing predictors rather than data problems.
Apply corrections (adding predictors, transformations, robust errors) appropriately.
Interpret how model adjustments affect coefficients and inference.
Read and interpret diagnostic plots critically.
14.2 Model assumptions
Linear models are a cornerstone of statistical analysis, widely used across scientific disciplines to explore relationships between variables. Their popularity stems from their simplicity, interpretability, and versatility. However, the reliability of linear models depends on meeting several critical assumptions:
-
Normality of residuals
- Residuals are “approximately” normally distributed - skewed is particularly bad
-
Homogeneity of variance
- Residuals have constant variance (consistent error not changing throughout model)
-
Linearity of relationships
- Predictors have a linear relationship with the outcome (important for continuous predictors)
-
Absence of influential outliers
- No single or few observations that unduly drive the model
-
Independence
- Observations are all equally independent (not in groups, batches or otherwise linked and not accounted for)
-
Low multicollinearity
- Predictors are not highly correlated with each other (makes it hard to determine which predictors are important)
When these assumptions are violated, the model’s conclusions can become misleading, leading to erroneous inferences and predictions. Diagnosing and addressing these violations is a crucial step in any linear modeling workflow. This chapter explores how to evaluate linear models, identify assumption violations, and apply appropriate corrective measures.
14.3 Reading Model Diagnostic Plots
Before any modeling, it’s crucial to know what you’re looking at when using diagnostic tools.
14.3.1 How to read check_model() plots
-
Posterior predictive check - density distribution of observed y against predicted y
How good is our model at “predicting” data that matches what we observed
Look at this for unusual patterns in predictions
-
Linearity
- Straight line = good
-
Normal Q–Q Plot – Tests normality of residuals.
Points on diagonal = good.
S-curve = skewed residuals.
-
Homogeneity of Variance – Checks for changing variance.
Horizontal line = good.
-
Upward slope = increasing variance.
- Random scatter = good.
Curved or funnel shape = assumption violation.
-
Influential Observations – Flags outliers/influential points.
- Points beyond Cook’s distance = potentially problematic.
Take a moment to interpret each plot rather than relying on a single diagnostic.
14.4 Missing variables
When learning statistics, it’s important to remember that the first step in diagnosing poor model residuals is to ensure that your model includes the correct predictors and interaction terms. Residuals reflect the difference between the observed and predicted values, and large or patterned residuals often indicate that the model is missing key information.
14.4.1 For example:
If a predictor that strongly affects the outcome is omitted, the model may fail to capture important variation, leading to biased predictions. If an interaction between two predictors (e.g., temperature and humidity) exists but is not included, the model might not adequately describe the relationship between predictors and the outcome.
14.4.2 Blood Pressure Data
We’ll use a simple dataset on blood pressure and physiological variables.
This dataset includes key physiological and demographic variables — Blood Pressure, Weight, Age, Albumin (a blood protein level), Pulse, and Stress. These variables are commonly studied in health and biological research to understand how physiological and psychological factors interact.
We are specifically interested in the effects of Weight and Blood albumin levels on blood pressure readings:
Call:
lm(formula = BP ~ Weight + Albumin, data = bp)
Residuals:
Min 1Q Median 3Q Max
-1.8932 -1.1961 -0.4061 1.0764 4.7524
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.6534 9.3925 0.602 0.555
Weight 1.0387 0.1927 5.392 4.87e-05 ***
Albumin 5.8313 6.0627 0.962 0.350
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.744 on 17 degrees of freedom
Multiple R-squared: 0.9077, Adjusted R-squared: 0.8968
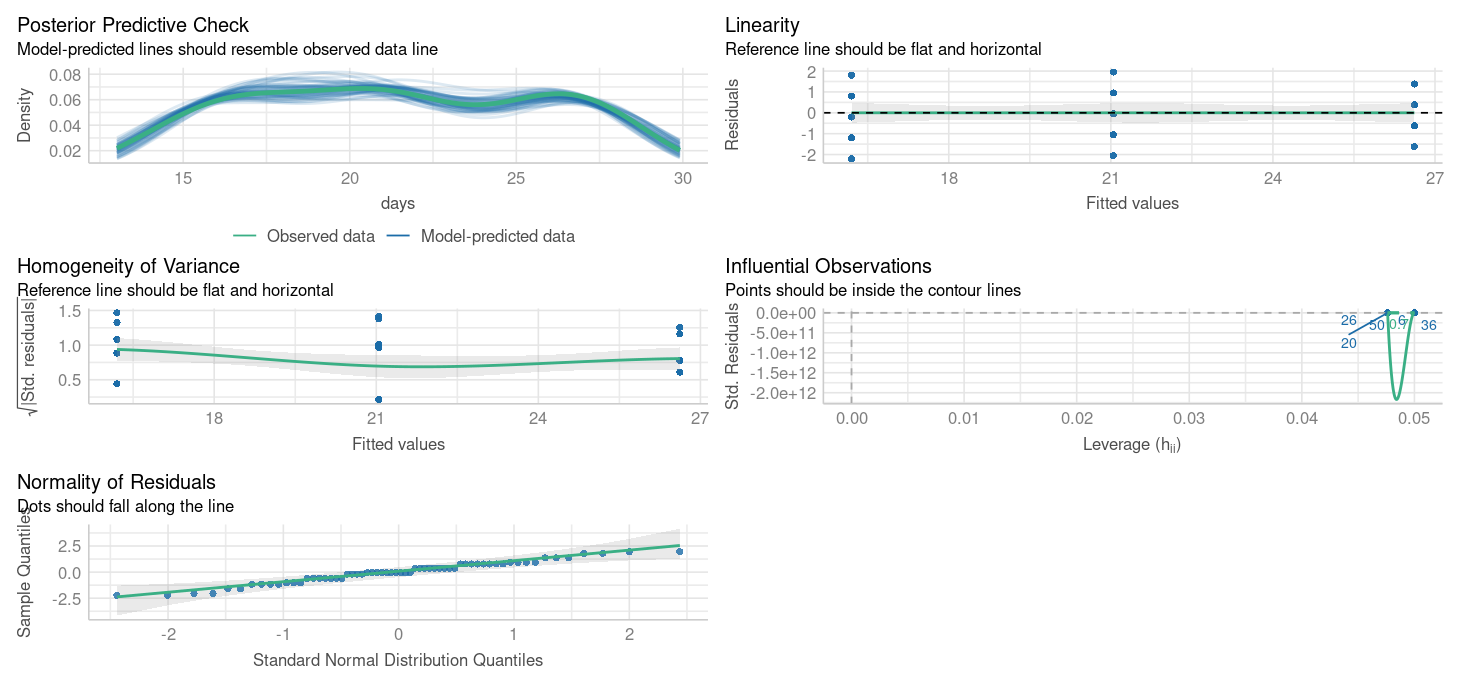
F-statistic: 83.54 on 2 and 17 DF, p-value: 1.607e-09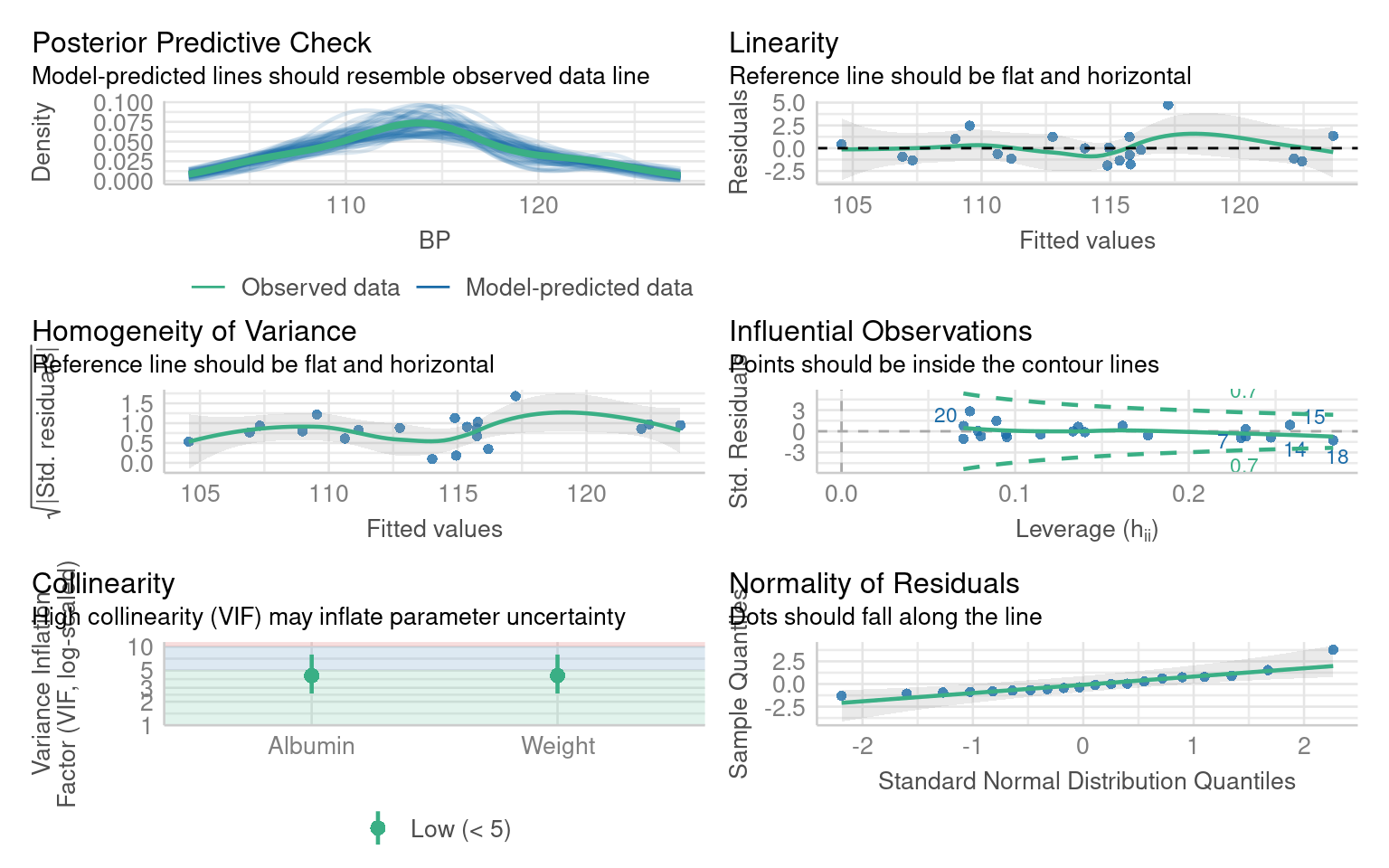
What are the issues with these model residuals?
There residuals do not fit the assumption of a normal distribution. In addition there are some non-linear patterns in the residuals that indicate this model may not be the best fit
14.4.3 Improving the blood pressure model
Residual patterns often signal missing information. If important predictors are omitted, residuals show structure instead of randomness.
Add the missing variable as an additional predictor:
Call:
lm(formula = BP ~ Weight + Albumin + Age, data = bp)
Residuals:
Min 1Q Median 3Q Max
-0.75810 -0.24872 0.01925 0.29509 0.63030
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -13.66725 2.64664 -5.164 9.42e-05 ***
Weight 0.90582 0.04899 18.490 3.20e-12 ***
Albumin 4.62739 1.52107 3.042 0.00776 **
Age 0.70162 0.04396 15.961 3.00e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.437 on 16 degrees of freedom
Multiple R-squared: 0.9945, Adjusted R-squared: 0.9935
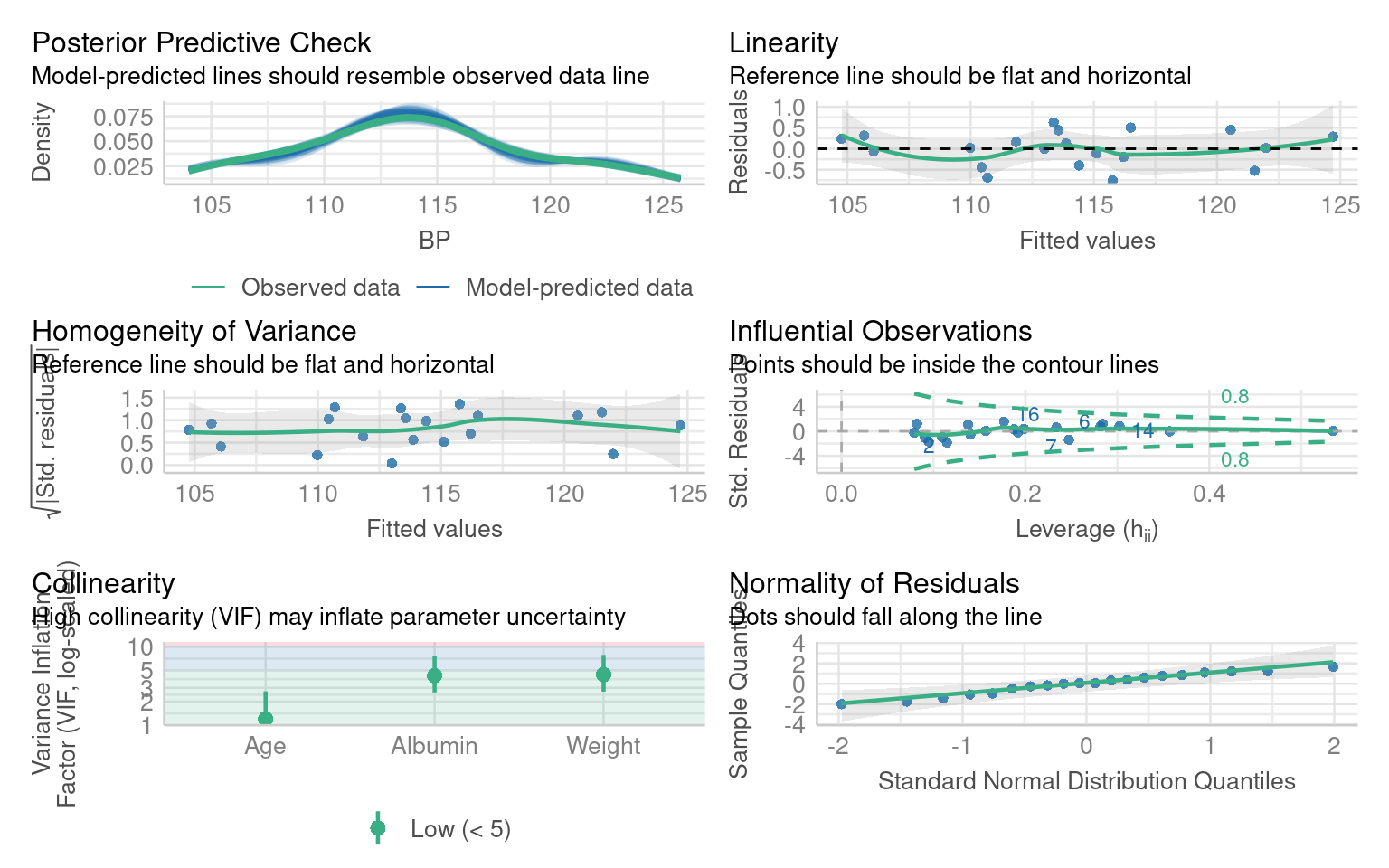
F-statistic: 971.9 on 3 and 16 DF, p-value: < 2.2e-1614.4.4 Interpretation Practice
Compare adjusted R² between the two models — did the fit improve?
Which predictors changed significance?
Does adding Age make biological sense for explaining blood pressure?
From this we can see that adding Age is an important covariate for our model. If we chose to include Pulse or Stress as well, that would be ok - they don’t make the model any worse - but they don’t appear to be particularly important.
From this we can learn that before we attempt any radical data transformations, we should check whether our model would fit the data better with the inclusion of an omitted variable.
When we do this, not only does our model fit the data better, but our understanding of the importance of our predictor variables changes as well. Previously we would have dismised Albumin levels as unimportant, now we see that when account for Age as a predictor of blood pressure, albumin levels are also a significant predictor.
14.5 Data transformations
When residuals remain non-normal or variance increases with fitted values, transformations can sometimes help.
Transforming the dependent variable (the variable you’re trying to predict) can help fix these issues by changing its scale to better match the assumptions of the model. Here’s how:
Non-normal residuals: If the dependent variable is heavily skewed (e.g., income or population size), transformations like taking the log(y) or square root (y) can make the distribution more symmetric.
Stabilize Variance: If the residuals show increasing or decreasing spread (heteroscedasticity), transformations can help make the variance more constant.
Linearise Relationships: Some relationships between the dependent and independent variables are non-linear. Transformations can make these relationships more linear, which linear models handle better.
14.5.1 Example Bacterial Growth
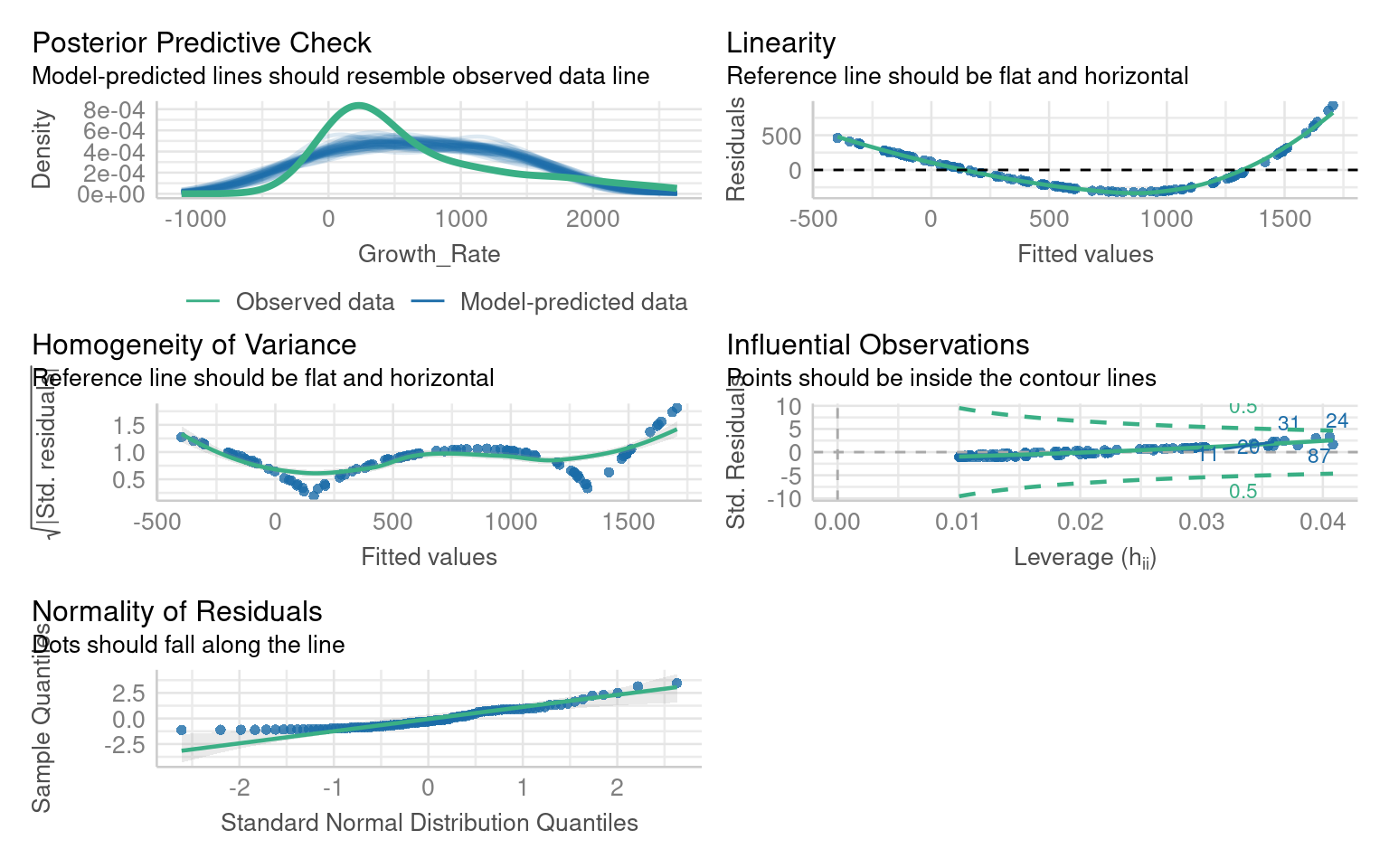
** What are the issues with this model?**
If we look at the residuals we see there are obvious issues with linearity, and heteroscedasticity and normality of the residuals - all of these criteria might be improved with the right data transformation
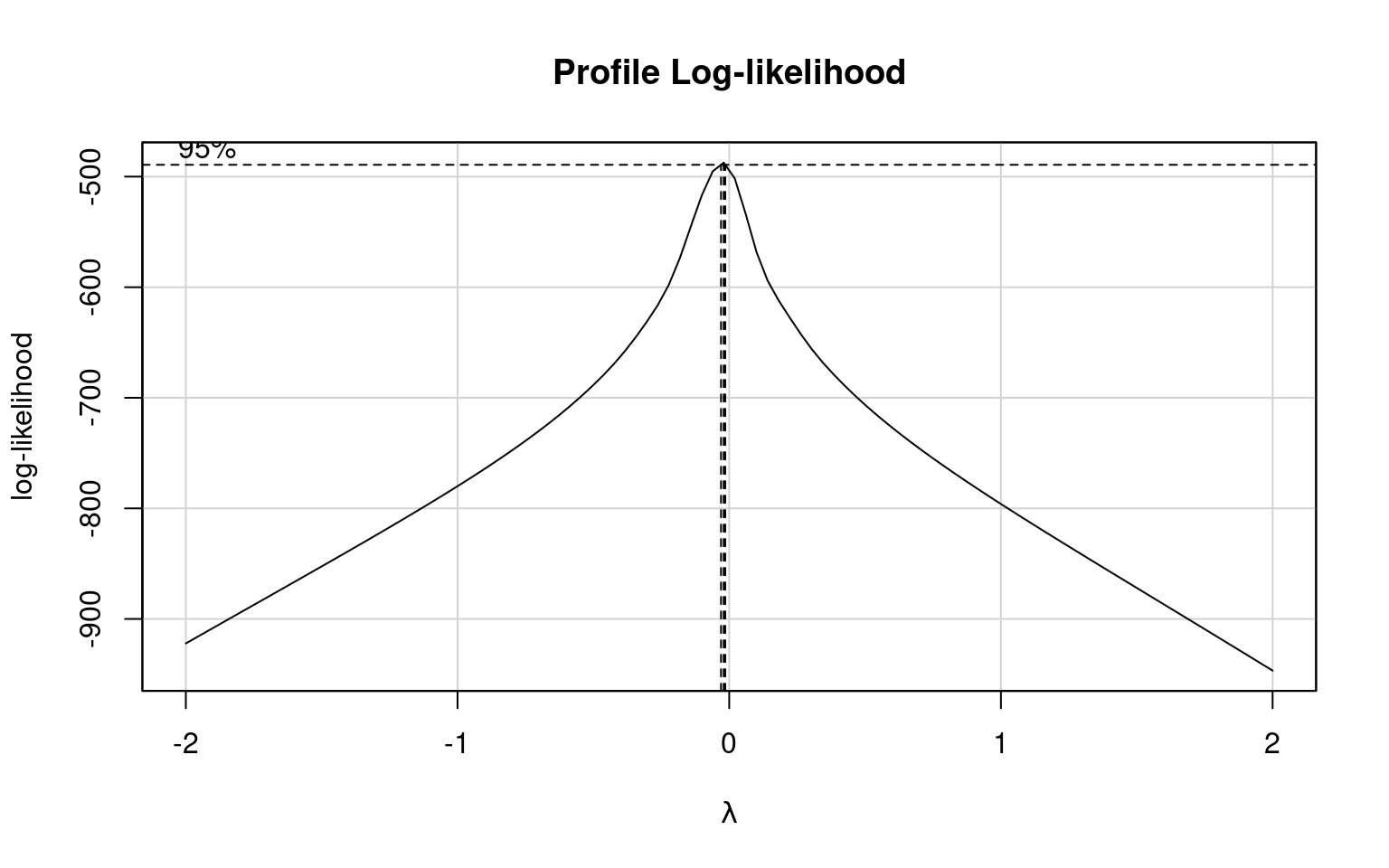
14.5.1.1 Boxcox
Box-Cox transformations help identify the best transformation for the dependent variable (y) in a linear model to improve fit, stabilize variance, and address non-normality. The method tests a family of power transformations:
How It Works: The Box-Cox method estimates the optimal value of 𝜆 (the power parameter) that makes the residuals closest to normality and stabilizes variance.
Common transformations include:
𝜆= 1: No transformation (original scale).
λ=0: Log transformation.
λ=0.5: Square root transformation.
Why Not Use 𝜆 Directly? The optimal 𝜆is often not a simple value like 0, 0.5, or 1. Using a fractional 𝜆(e.g., 0.27) creates a less interpretable transformation. Instead of applying the exact 𝜆 it’s better to choose a nearby, familiar transformation (e.g., log or square root) for ease of interpretation while still improving the model.
| lambda value | transformation |
|---|---|
| 0.0 | log(Y) |
| 0.5 | sqrt(Y) |
| 1.0 | Y |
| 2.0 | Y^1 |
What is the optimal transformation for our dependent variable according to the Box-Cox transformation
Apply this transformation to your dependent variable
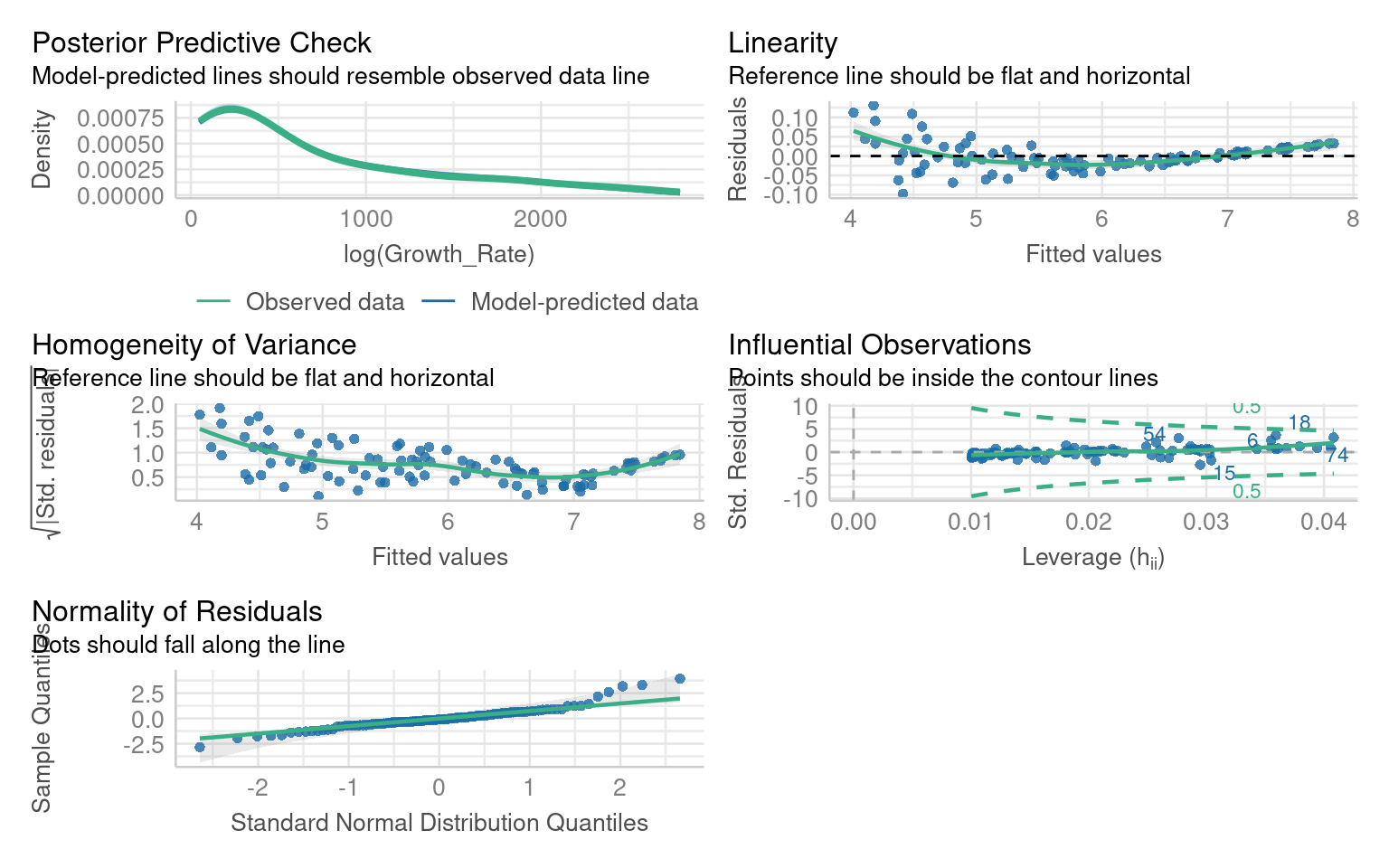
Warning: Non-normality of residuals detected (p < .001).
Warning: Heteroscedasticity (non-constant error variance) detected (p < .001).14.5.2 Interpretation Practice
Did the transformation improve residual normality or variance?
How has the pattern of residuals changed?
How does interpreting coefficients differ now that the dependent variable is on a log scale?
Transformations can correct skewness or variance issues, but make interpretation harder since coefficients relate to transformed values.
14.6 Heteroscedasticity
Heteroscedasticity occurs when the residuals (errors) of a linear model have non-constant variance across the range of the predictors. Even if the data appears normal and linear, heteroscedasticity can still be a problem.
Imagine a situation where:
Residuals are larger (more spread out) for higher values of a predictor, or smaller for lower values.
Although the relationship between the predictors and the response variable is linear, the variance of the errors changes systematically.
14.6.0.1 Why Does This Matter?
Misleading Inference: Heteroscedasticity doesn’t bias the coefficients of the model, but changing variance (heteroscedasticity) invalidates standard errors, leading to incorrect p-values and confidence intervals.
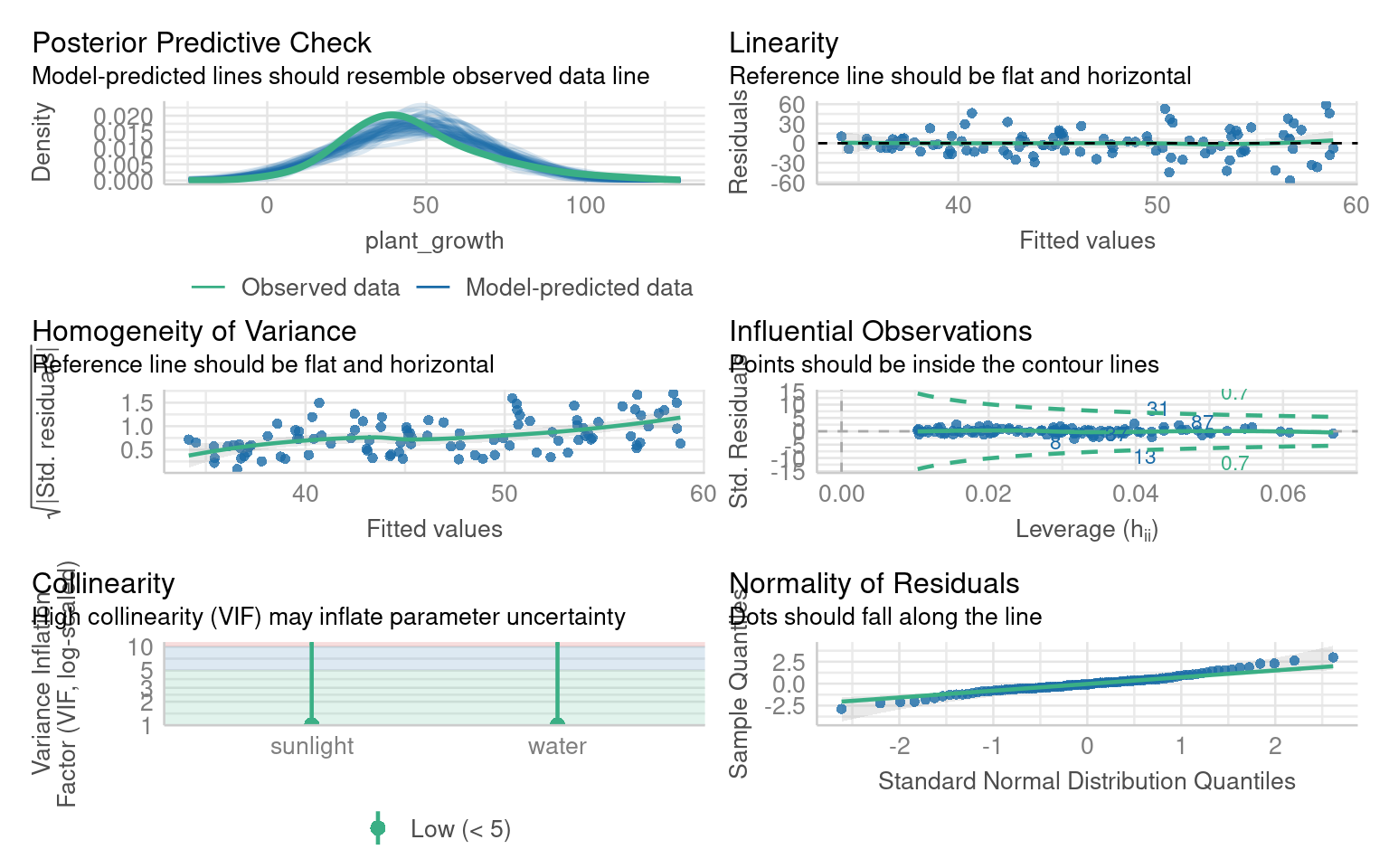
Warning: Heteroscedasticity (non-constant error variance) detected (p < .001).
OK: residuals appear as normally distributed (p = 0.199).What are the issues with these model residuals?
14.6.1 Robust errors
If coefficients look fine but residual variance is non-constant, we can adjust the standard errors using robust covariance estimators:
In R we can use the package Zeileis & Lumley (2024) to help provide robust errors:
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 30.423746 6.804327 4.4712 2.112e-05 ***
sunlight 2.824254 0.919202 3.0725 0.002755 **
water 0.057812 0.398499 0.1451 0.884952
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 114.6.2 Interpretation Practice
Compare the standard errors between the default and robust outputs.
Did any predictors change in significance?
What does this imply about the reliability of your inference?
The emmeans package doesn’t support the sandwich model outputs directy, but we can supply the same adjustments when running the emmeans function
# Get robust covariance matrix
robust_vcov <- vcovHC(plant_model, type = "HC1")
# Use emmeans with robust covariance
# specify lists to get predictions for continuous variables
emmeans::emmeans(plant_model, specs = ~ sunlight + water,
at = list(sunlight = c(1:10),
water = 1:20),
vcov. = robust_vcov)14.7 Non-linearity
In linear models, we assume that the relationship between the predictors (independent variables) and the response (dependent variable) is linear—that is, a change in a predictor is associated with a proportional change in the response. However, real-world data often deviate from this assumption, and relationships can be non-linear. For example, the effect of increasing temperature on plant growth might plateau after an optimal range, or the impact of exercise on health might diminish after a certain intensity.
Let’s revisit the janka data from our introductory regression chapter
We originally fitted a simple regression model of wood density as a predictor of timber hardness:
Call:
lm(formula = hardness ~ dens, data = janka)
Residuals:
Min 1Q Median 3Q Max
-338.40 -96.98 -15.71 92.71 625.06
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1160.500 108.580 -10.69 2.07e-12 ***
dens 57.507 2.279 25.24 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 183.1 on 34 degrees of freedom
Multiple R-squared: 0.9493, Adjusted R-squared: 0.9478
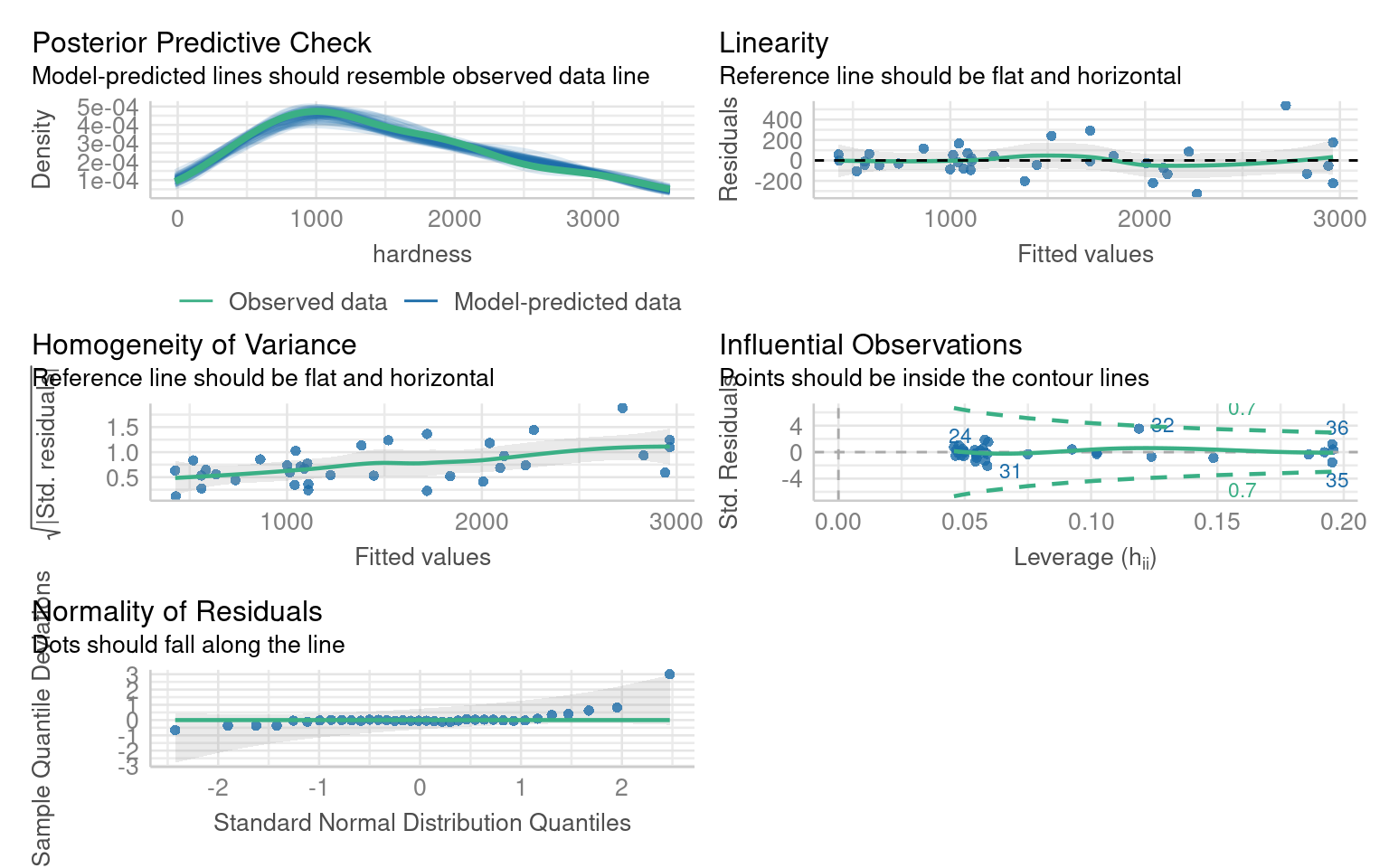
F-statistic: 637 on 1 and 34 DF, p-value: < 2.2e-16If we inspect this model we can see there are issues with non-linearity, heteroscedasticity and non-normality:
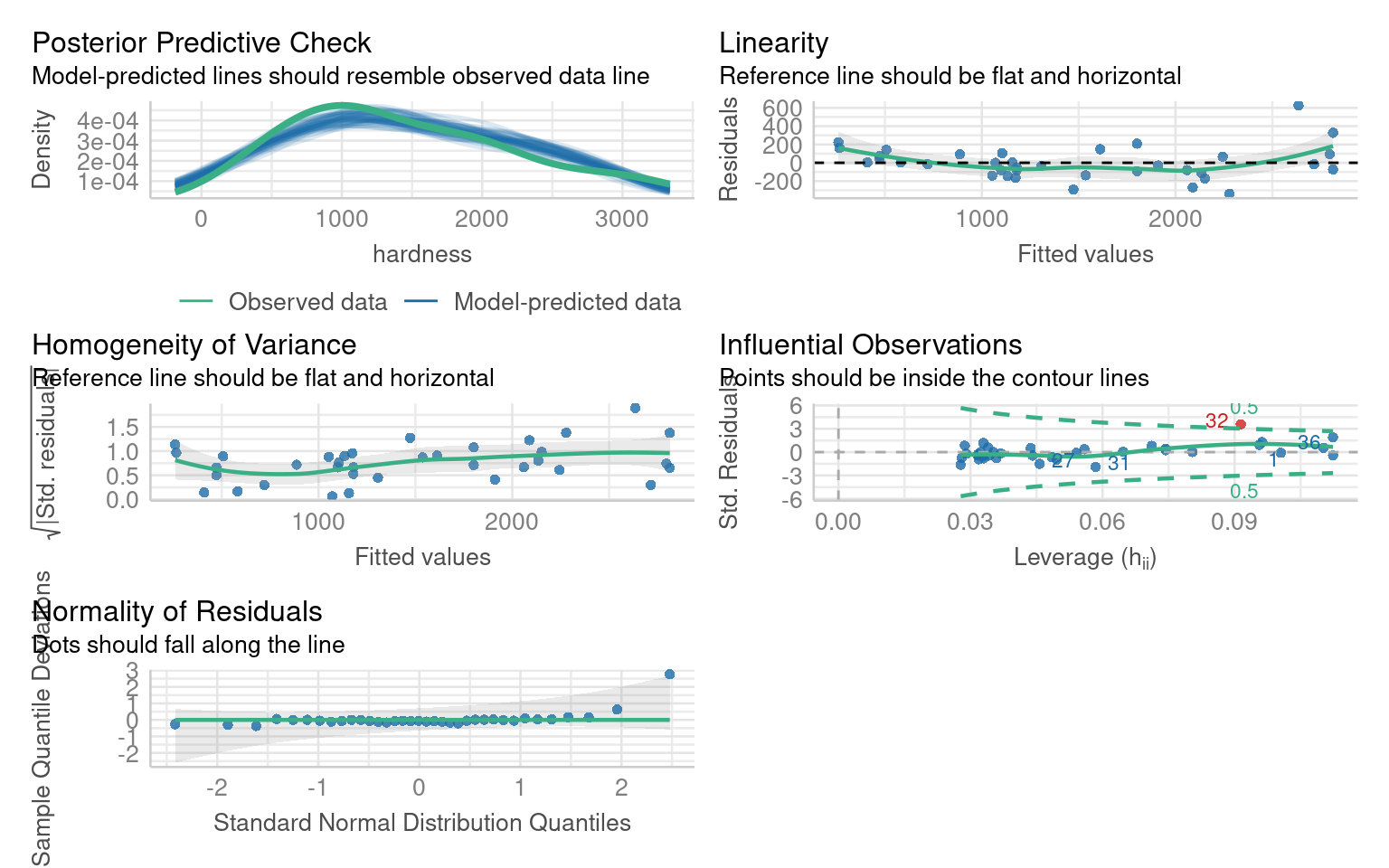
14.7.1 Transformation
Which model does a Boxcox transformation suggest is most appropriate?
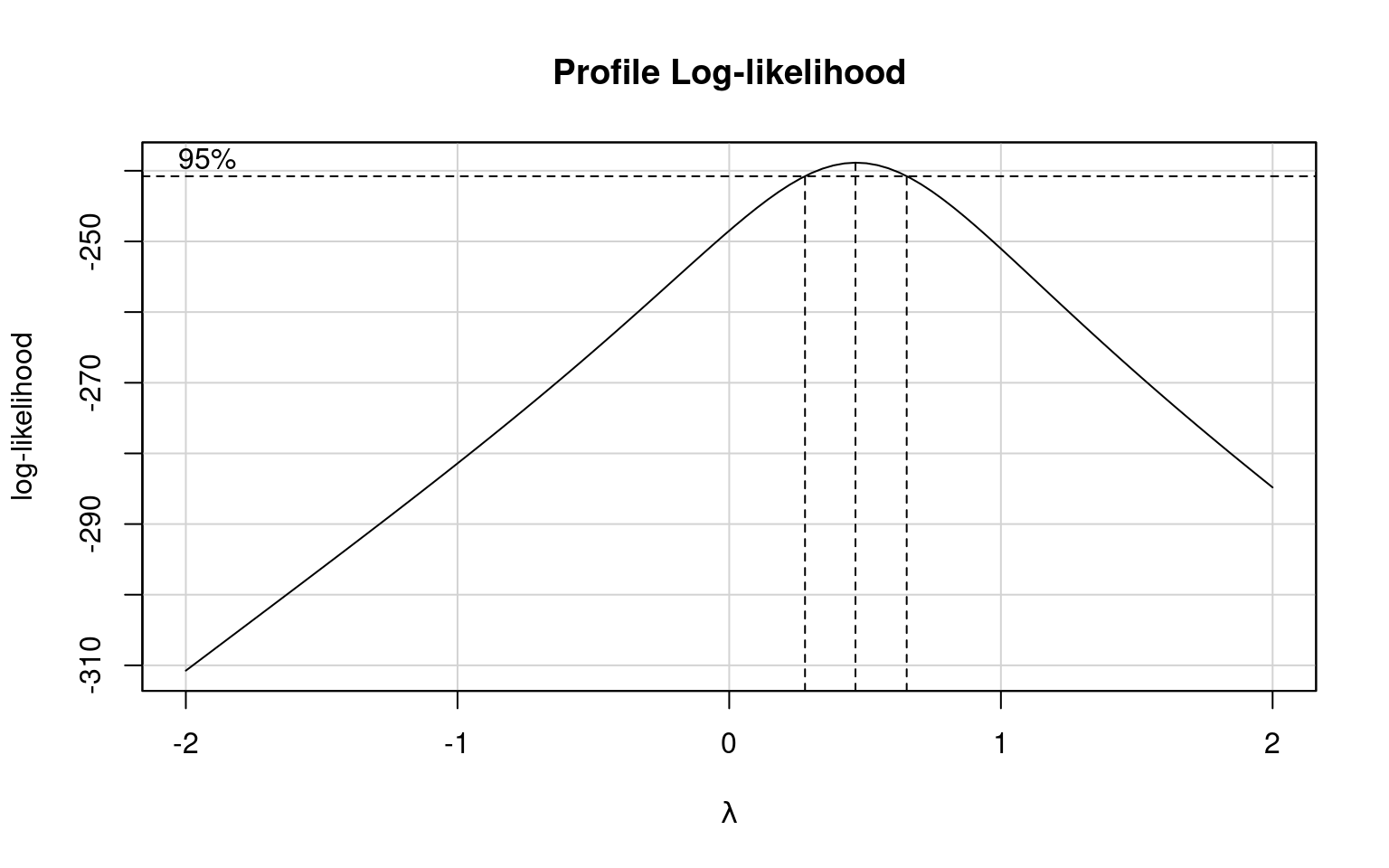
We can fit both a sqrt and log transformed model and compare them:
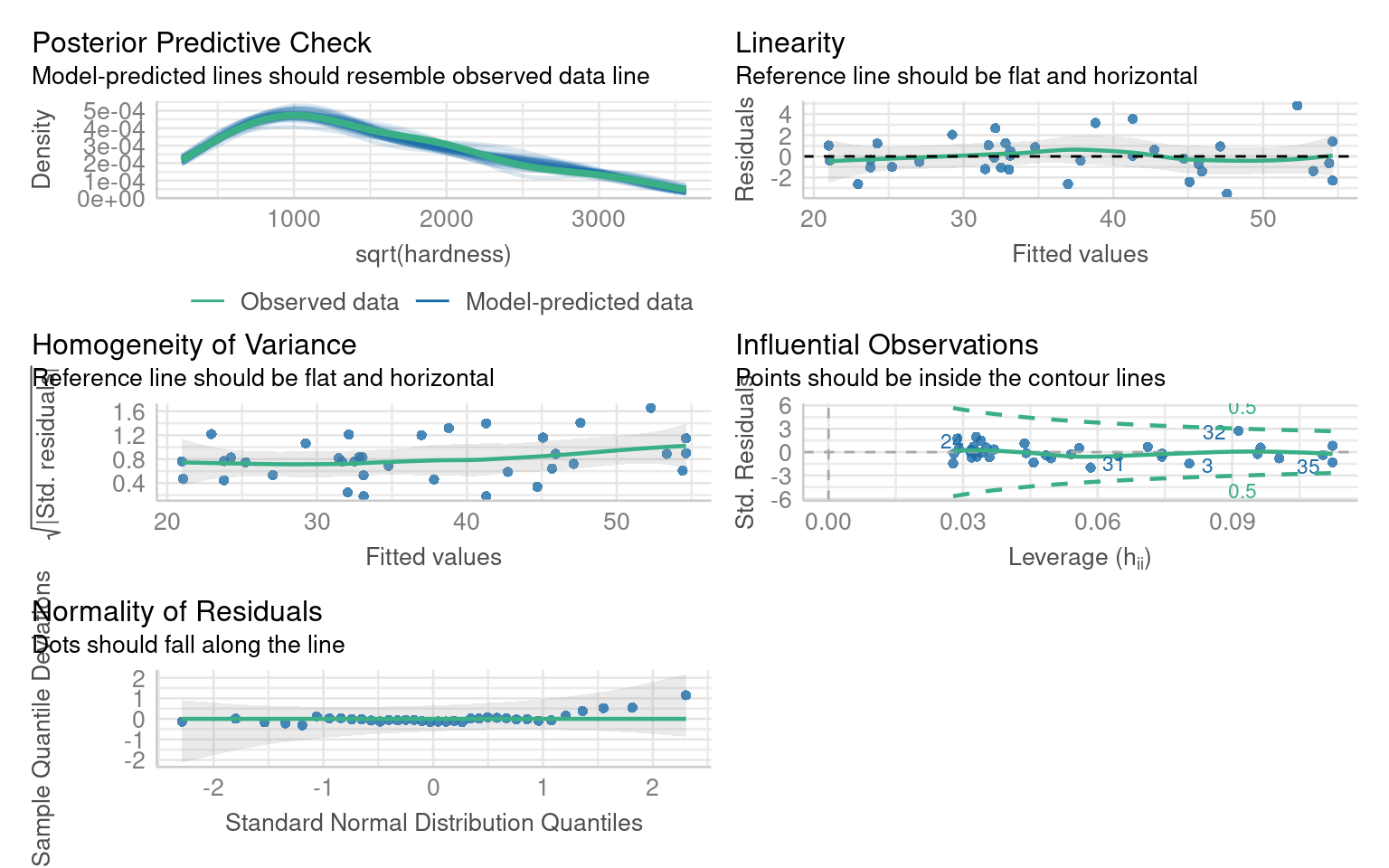
This model does not significantly improve the normality or heterogeneity of the residuals, but does improve linearity
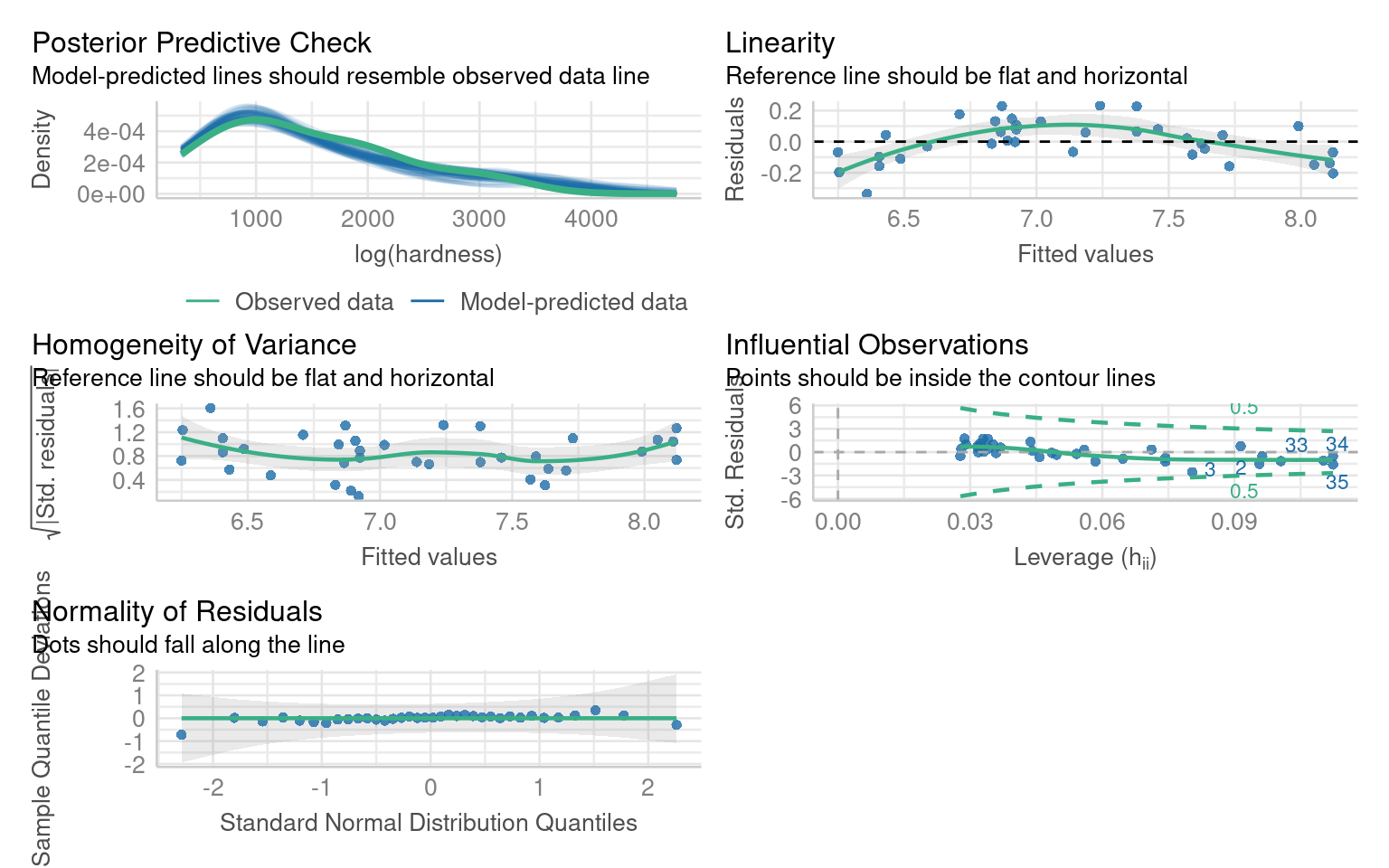
This model does improve normality and heterogeneity, but introduces an overcorrection on linearity
14.7.2 Polynomials
Polynomials are mathematical expressions that allow us to model non-linear relationships between predictors and the response variable in a linear model. By including polynomial terms (e.g., x^2, x^3), we can create more flexible models to capture curvature in the data.
14.7.2.1 What Does poly(x, 2) Do?
-
poly(x, 2)creates a second-degree polynomial (quadratic). - It models the relationship as: [ y = _0 + _1 x + _2 x^2 + ]
- This adds curvature to the model, allowing it to capture a U-shape or an inverted U-shape.
14.7.2.1.1 Example:
If the data looks like a parabola (e.g., plant growth increasing with temperature up to a point, then declining), a second-degree polynomial can model this.
14.7.2.2 What Does poly(x, 3) Do?
poly(x, 3)creates a third-degree polynomial (cubic).It models the relationship as: [ y = _0 + _1 x + _2 x^2 + _3 x^3 + ]
This allows for more flexibility in the curve, capturing an S-shaped pattern or two bends in the data.
14.7.2.2.1 Example:
If the relationship involves multiple changes in direction (e.g., population growth speeding up, then slowing down, and finally stabilizing), a cubic polynomial can model this.
14.7.2.3 Janka data
In our example the slight curvature in the model could be addressed with a quadratic term:
But we can see this does not address the issues of heteroscedasticity or non-normality of residuals.
We know that the log transformed dependent variable did address this, but introduced unwarranted curvature - we could address this with a polynomial:
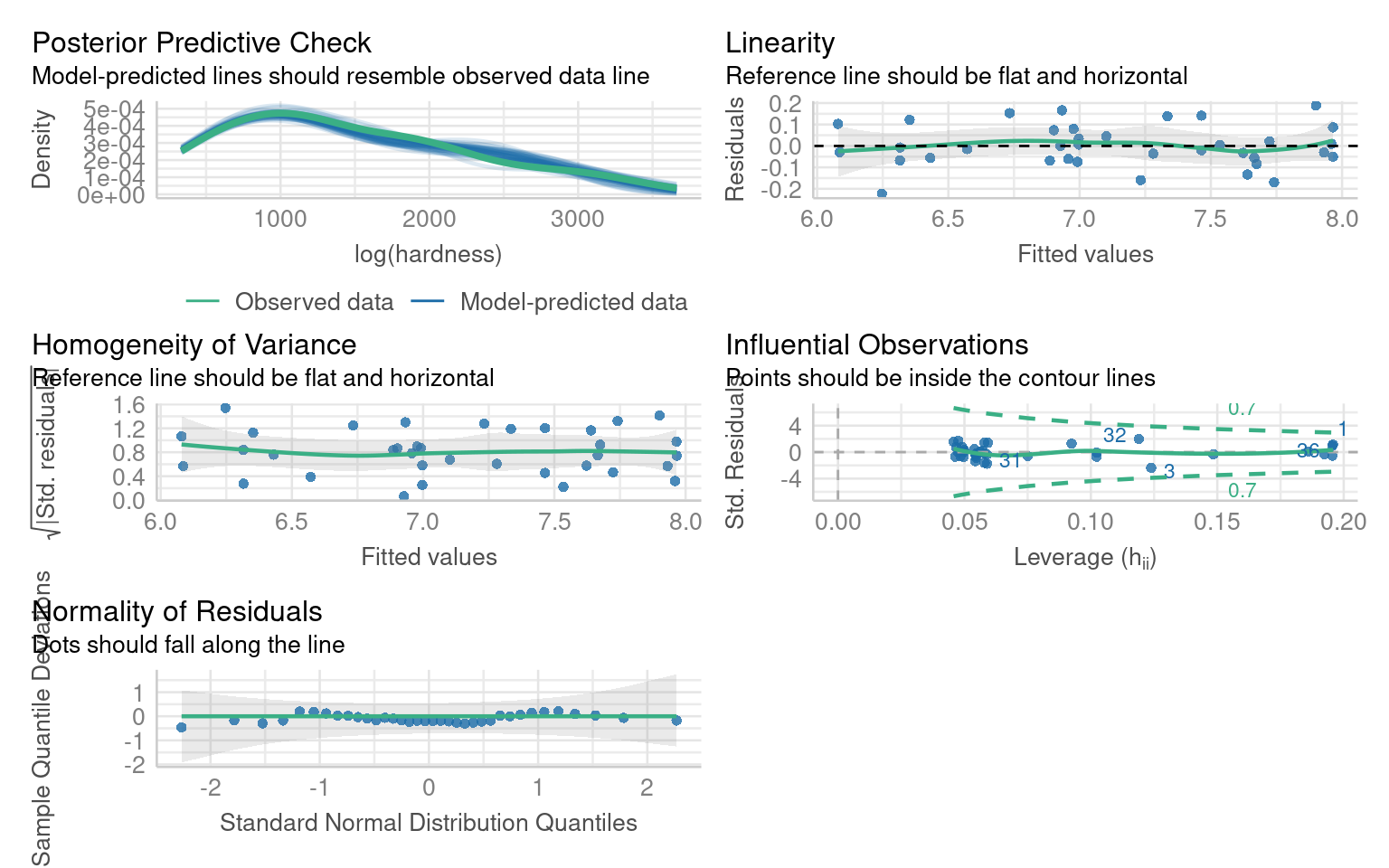
This produces a much better fitting model - but what about interpretation?
Call:
lm(formula = log(hardness) ~ poly(dens, 2), data = janka)
Residuals:
Min 1Q Median 3Q Max
-0.22331 -0.05708 -0.01104 0.07500 0.18871
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.1362 0.0168 424.896 < 2e-16 ***
poly(dens, 2)1 3.3862 0.1008 33.603 < 2e-16 ***
poly(dens, 2)2 -0.5395 0.1008 -5.354 6.49e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1008 on 33 degrees of freedom
Multiple R-squared: 0.9723, Adjusted R-squared: 0.9706
F-statistic: 578.9 on 2 and 33 DF, p-value: < 2.2e-16We now have an excellent fitting model - but this has come at the cost of interpretation.
The coefficients are not directly interpretable
The relationship with the dependent is on a log scale
14.7.2.4 Polynomial summary
Polynomials can help improve the fit of a model when there is a non-linear relationship. When you do this focus on the overall model fit and visualizations, as the coefficients from poly() are not directly tied to raw powers of x. Because of the lack of coefficient interpretation use this with caution
poly(x, 2) (Quadratic): Adds curvature, useful for simple bends like U-shapes.
poly(x, 3) (Cubic): Adds more flexibility, useful for S-shaped or complex curves.
In our advanced modules we will look at Generalised Linear Models which retain the benefits of modelling non-linear relationships with better interpretability
14.8 Multicollinearity
Multicollinearity occurs when predictor variables in a linear model are highly correlated, which can make it hard to isolate the effect of individual predictors. Standard errors inflate and p-values are higher
14.8.1 Example
The Mammals dataset includes information about various mammal species, focusing on their physical characteristics and ecoogicial traits.
We will look at the following traits:
-
Physiological Variables:
-
total_sleep: The average number of hours a species sleeps per day. -
life_span: The average lifespan of the species in years. -
gestation: The average gestation period (pregnancy duration) in days. -
brain_wt: Brain weight of the species in kilograms. -
body_wt: Body weight of the species in kilograms.
-
-
Ecological and Behavioral Variables:
-
predation: A categorical variable indicating the species’ risk of predation (e.g., low, medium, high). -
exposure: A categorical variable describing how exposed the species is while sleeping. -
danger: A categorical variable summarizing the overall danger level to the species.
-
14.8.1.1 Correlations
We can get a good idea of which variables might produce multicollinearity by first seeing which are highly correlated:
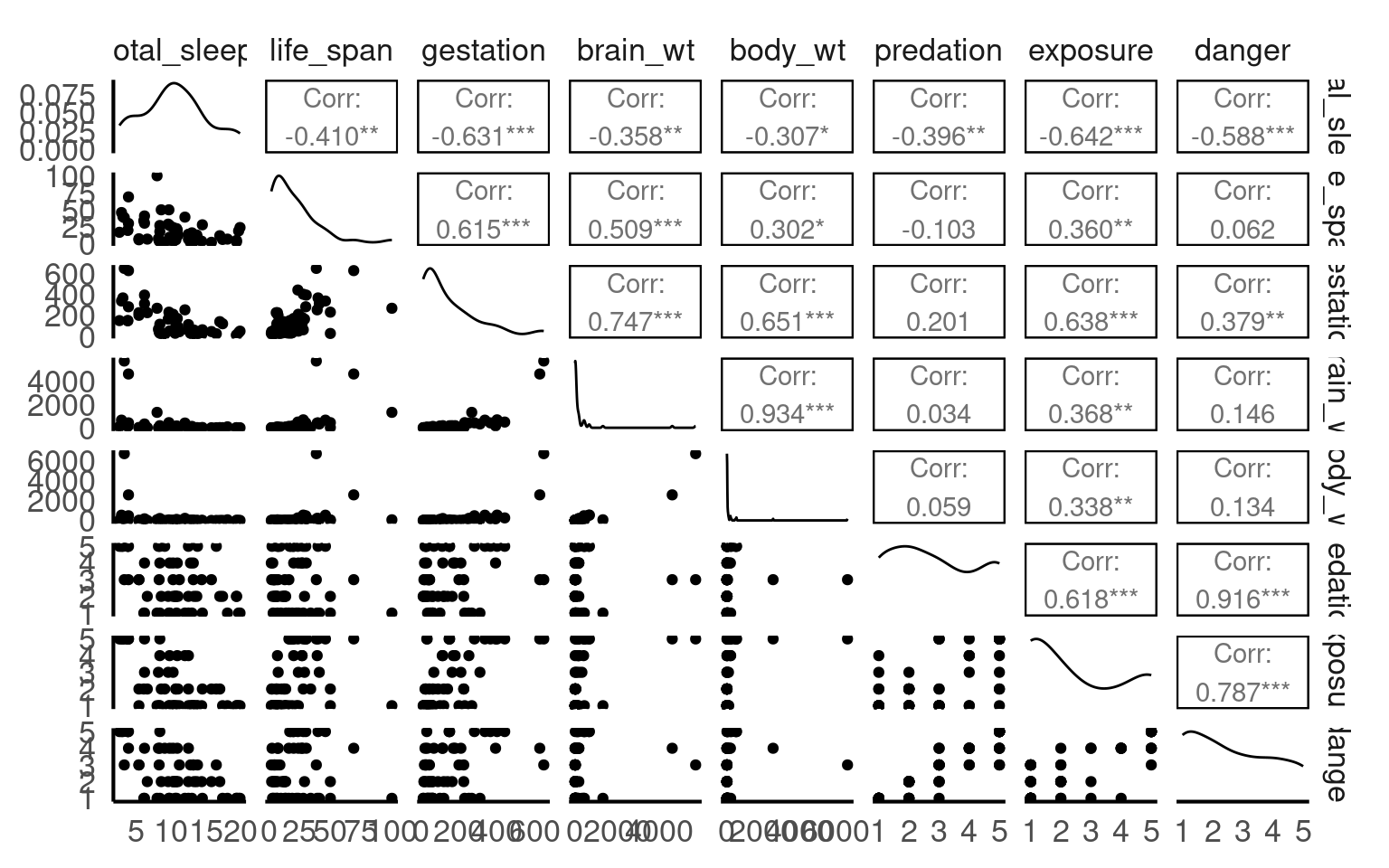
Which sets of variables have the highest correlations?
Danger and predation
Brain weight and Body weight
14.8.2 Fitting a model
I am fitting a model to establish the behavioural and physiological characteristics that predict sleep:
Call:
lm(formula = total_sleep ~ life_span + gestation + brain_wt +
body_wt + predation + exposure + danger, data = mammals)
Residuals:
Min 1Q Median 3Q Max
-5.8931 -1.9556 0.0842 1.4620 6.5572
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 16.603699 1.078176 15.400 < 2e-16 ***
life_span -0.039830 0.035366 -1.126 0.266323
gestation -0.016465 0.006214 -2.650 0.011230 *
brain_wt 0.002319 0.001614 1.437 0.157923
body_wt -0.001601 0.001464 -1.094 0.280039
predation 2.393361 0.971101 2.465 0.017789 *
exposure 0.632923 0.558573 1.133 0.263448
danger -4.508571 1.186118 -3.801 0.000449 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.846 on 43 degrees of freedom
(11 observations deleted due to missingness)
Multiple R-squared: 0.682, Adjusted R-squared: 0.6302
F-statistic: 13.17 on 7 and 43 DF, p-value: 6.364e-09The model summary suggests that “danger” and “predation” are the most likely predictors of sleep duration
The model residual checks indicate this is an excellent model fit but with high multicollinearity:
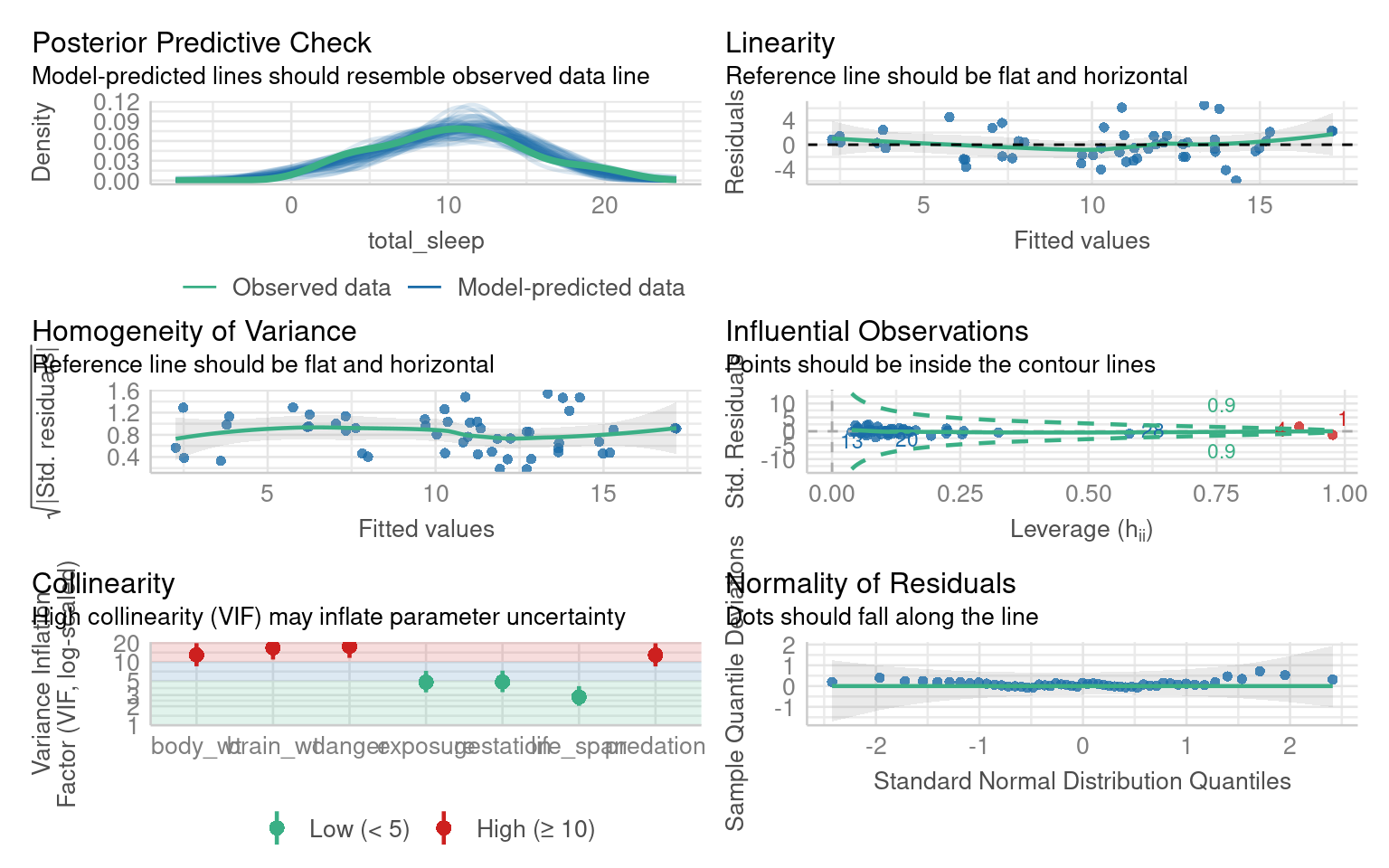
14.8.3 Correcting for multicollinearity
You may come across methods that describe correcting for multicollinearity but in reality there is no need to do so. We should report multicollinearity and that we have some uncertainty over which predictors might be causing and observed changes.
14.9 Outliers
Outliers have been left to last because they should be dealt with last. Outliers can be the result of a poor model fit, non-linearity or non-normal residuals. As such they may be resolved when attempting to fix other issues with a model.
Call:
lm(formula = Femur ~ Humerus, data = titanosaurs)
Residuals:
Min 1Q Median 3Q Max
-0.28305 -0.11302 -0.02654 0.08374 0.43352
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.33387 0.09489 3.519 0.00245 **
Humerus 0.84261 0.08573 9.829 1.16e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1792 on 18 degrees of freedom
Multiple R-squared: 0.8429, Adjusted R-squared: 0.8342
F-statistic: 96.61 on 1 and 18 DF, p-value: 1.164e-08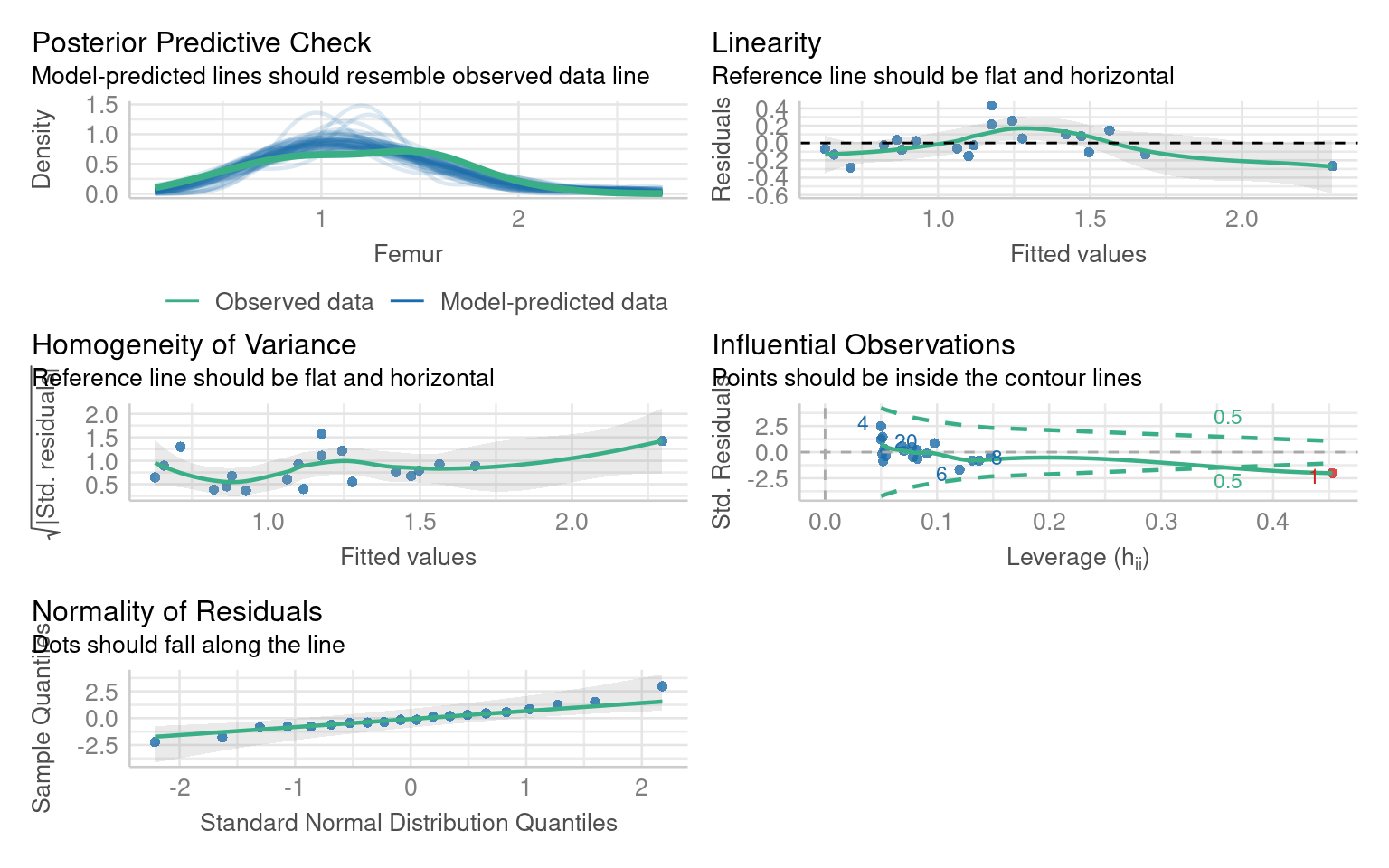
In this model the residual fits are good (perhaps slight non-linearity, but lets leave that for now). But we have one outlier.
Assuming all other aspects of the model are good, we can check whether this outlier is affecting our model interpretations by removing it and evaluating the model without it
The diagnostic plot indicates that the data is from row 1
The easiest way to address this is to use co-ordinates:
Call:
lm(formula = Femur ~ Humerus, data = titanosaurs2)
Residuals:
Min 1Q Median 3Q Max
-0.24494 -0.06682 0.00366 0.04784 0.40959
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.2095 0.1025 2.045 0.0567 .
Humerus 0.9909 0.1023 9.688 2.46e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1622 on 17 degrees of freedom
Multiple R-squared: 0.8466, Adjusted R-squared: 0.8376
F-statistic: 93.85 on 1 and 17 DF, p-value: 2.46e-08Importantly the model estimate haschanged, but it is still a significant predictor, and there are no further outliers:
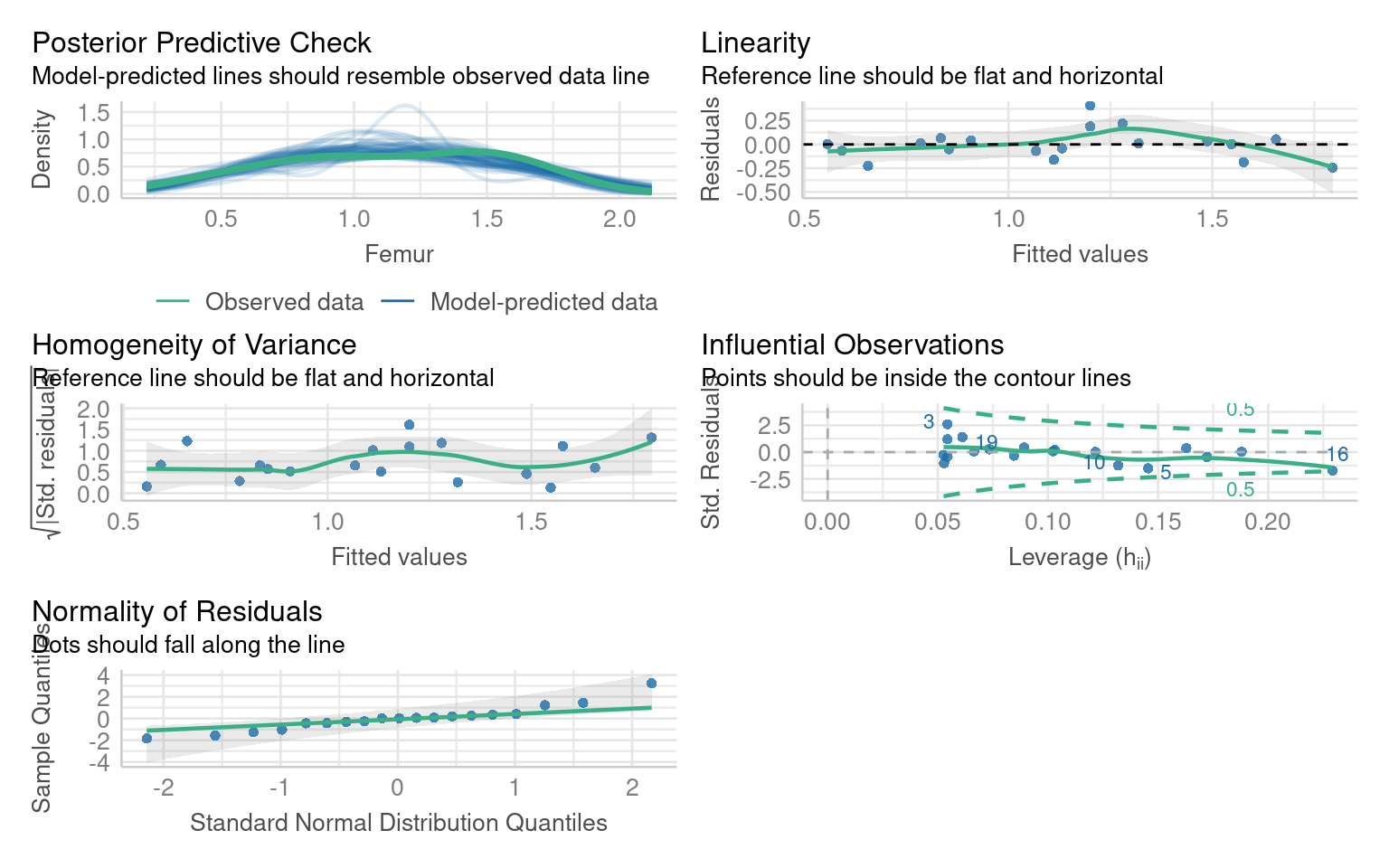
If you remove an outlier causing leverage you must report it, and you should compare the models and report whether it has altered any of your coefficient estimates and significant predictors.
14.10 Summary checklist
| Problem | How to detect | Solution |
|---|---|---|
| Non-normal residuals | Q–Q plot | Transform dependent variable |
| Heteroscedasticity | Residual vs fitted plot | Use robust SEs or transform response |
| Non-linearity | Residual patterns | Add predictors or transform Y |
| Outliers | Cook’s distance | Investigate, report, possibly remove |
| Multicollinearity | VIF > 5 | Report |
14.11 Reporting Diagnostics
When reporting results, include:
Model formula, sample size, and R².
Diagnostic checks performed and results (normality, variance, outliers).
Any transformations applied and reasoning.
Whether outliers or predictors were removed.
How model fit changed after corrections.